L'IA n'a pas rendu l'ingénierie moins chère. Elle a déplacé la facture en aval.
Chaque argumentaire d'outil de codage par IA vous vend la même chose : la vitesse. Écrire la fonctionnalité en minutes, pas en jours. Livrer davantage avec moins de monde. Les démos sont réelles — le premier jet arrive vraiment en quelques secondes.
Puis le trimestre se clôt, et la facture surgit là où vous ne regardiez pas.
Une nouvelle étude d'Entelligence — un éditeur, et j'y reviendrai — a mis un chiffre sur l'endroit où elle surgit. Sur plus d'un million de pull requests issues de 2 444 organisations d'ingénierie, ils ont suivi où l'effort d'ingénierie assisté par IA atterrit réellement. Le constat phare : pour chaque dollar qu'une équipe dépense en IA de codage, environ 18 centimes deviennent du produit livré. Les 82 autres sont consommés avant même qu'une fonctionnalité n'arrive entre les mains d'un utilisateur — dépensés à corriger, reprendre et relire ce que les outils ont généré.
Je ne lis pas ce chiffre depuis le siège de l'investisseur, ni depuis celui de l'éditeur. Je le lis depuis celui que j'occupe depuis vingt ans : la personne qui doit défendre une ligne de coût IA devant un directeur financier et tenir l'astreinte qui rattrape ce que les outils ont livré. Et depuis ce siège-là, les 82 centimes ne sont pas du gaspillage. C'est la part du métier qui n'a pas été automatisée — et c'est le meilleur argument que j'aie vu cette année pour expliquer pourquoi l'ingénieur est précisément la part qu'on ne peut pas banaliser.
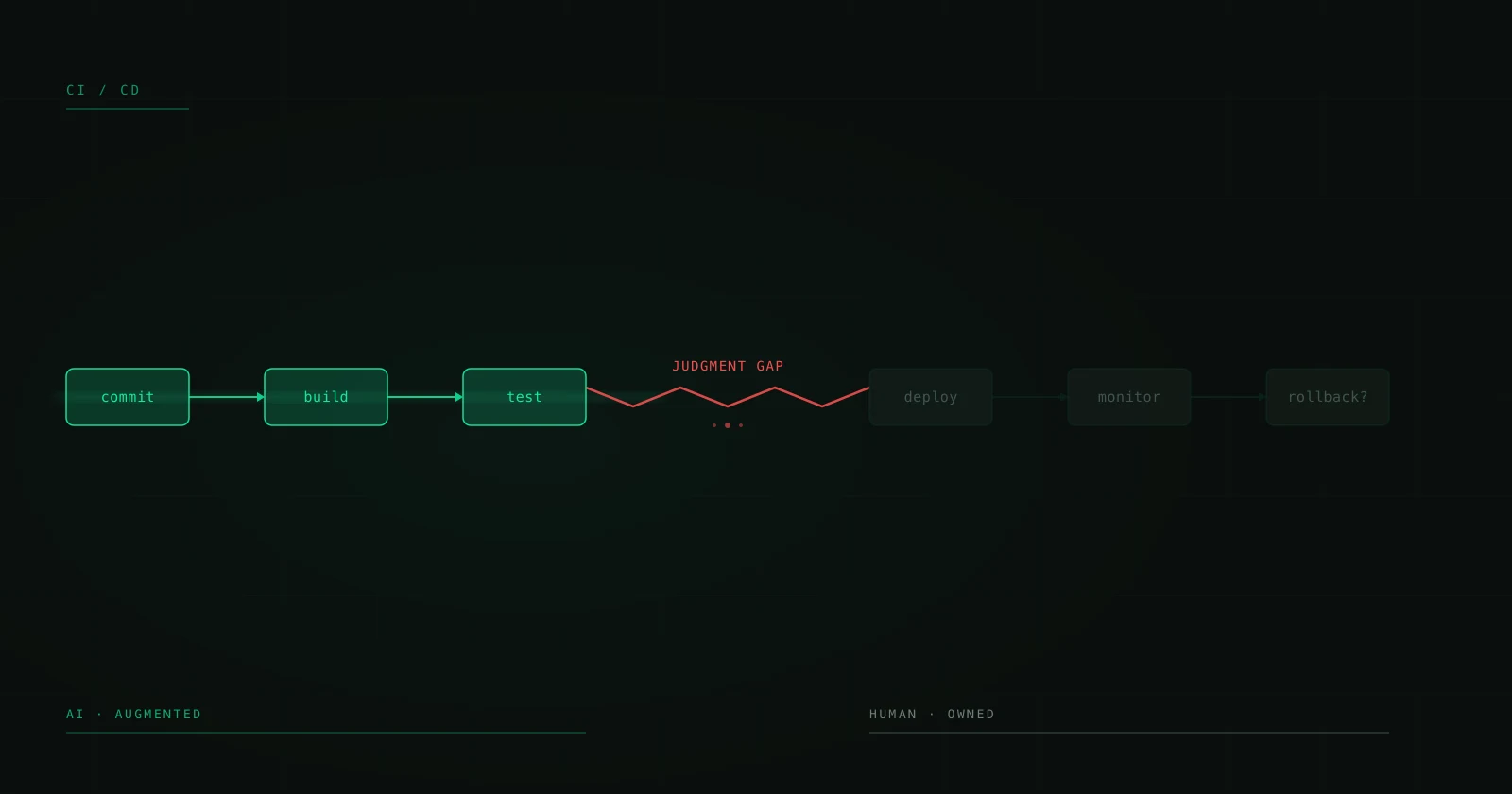
L'IA a rendu une seule chose bon marché : le premier jet
Retirez le marketing à un assistant de codage par IA, et ce qu'il vend, c'est un premier jet plus rapide. Il génère du code plausible à partir du contexte local — le fichier où vous êtes, la fonction au-dessus, les motifs qu'il a vus un million de fois. C'est réellement précieux, et c'est réellement bon marché aujourd'hui.
Ce qu'il ne sait pas faire, c'est reconnaître lequel de ces motifs a déjà échoué dans votre production le mois dernier. Il écrit depuis le dépôt, jamais depuis la réalité : quel cas limite vous avez tenté puis annulé, quelle nouvelle tentative « évidente » a fait tomber le service de paiement en mars, pourquoi ce contrôle de nullité que tout le monde n'arrête pas de supprimer est porteur. Le modèle est le moteur, et le moteur est devenu bon marché — j'ai longuement expliqué pourquoi un moteur bon marché ne fait pas une voiture bon marché. Générer du code a toujours été la partie facile. Rendre le code généré vrai en production, voilà la partie difficile, et rien dans un premier jet plus rapide ne la rend plus simple.
Les 82 centimes, c'est la part que seuls vos ingénieurs peuvent faire
Regardez comment l'étude décompose le dollar, et le cadrage du « gaspillage » s'effondre. Sur ces 82 centimes : environ 44 vont au travail réactif — corriger des bugs et maintenir les systèmes en marche —, 27 à la reprise du code qui n'a pas survécu au contact de la réalité, et 11 à la revue. Chacun d'eux est une décision de jugement en aval de la génération. Chacun, c'est le travail de décider si la chose plausible que le modèle a écrite est la bonne chose à livrer.
Ce dollar ne s'est pas évaporé. Il a changé de place — de la frappe du code vers sa vérification, son intégration et son exploitation. C'est le même mouvement que je ne cesse de pointer : la valeur grimpe dans la pile, de la couche que le modèle sait vous tendre vers celle qu'il ne sait pas. Plus la génération devient bon marché, plus votre dollar se concentre sur la part qui exige un humain ayant déjà livré. Appelons cela la part de travail réactif — et pour l'organisation médiane de ce jeu de données, c'est 44 % de toute la capacité d'ingénierie, avant même de compter la longue traîne où elle dépasse les trois quarts.
Les annulations grossissent plus vite que le travail qui les engendre
Voici le chiffre qui devrait inquiéter un CTO plus encore que les 82 centimes. Sur douze semaines, l'étude a vu le volume hebdomadaire de pull requests grimper de 2,6× — et les PR annulées grimper de 3,7×. L'échec se compose plus vite que la production. Vous ne livrez pas seulement davantage ; vous livrez davantage de choses qu'il faudra retirer.
Le mécanisme n'a rien de mystérieux, et ce n'est pas que les ingénieurs soient devenus mauvais. C'est que la couche de revue n'a jamais suivi le volume. Quand vous multipliez par 2,6× l'entrée d'un processus de vérification sans faire croître la vérification, le taux de fuite grimpe par définition. Le rapport le montre crûment : près de la moitié des PR sont approuvées en moins d'une heure, la plupart des commentaires de revue sont du bruit généré par des bots, et environ un cinquième seulement des commentaires donnent lieu à une action. Une ligne sur quatre écrite chaque semaine est jetée dans cette même semaine. Vous pouvez générer du code à la vitesse de la machine. Vous ne pouvez pas le relire à la vitesse de la machine et continuer d'appeler ça une revue — et l'écart entre ces deux vitesses, c'est exactement de là que viennent les annulations.
C'est le chiffre d'un éditeur — voici pourquoi j'en crois quand même la forme
Maintenant, la partie que la plupart des reprises médiatiques ont sautée. Entelligence vend le remède. Leur produit boucle « la boucle entre le code et la production » — qui se trouve être, commodément, exactement ce que le rapport conclut qu'il vous manque. Quand le vendeur d'un chiffre profite de votre alarme, décotez-le. Toujours.
Deux autres réserves que le rapport est assez honnête pour énoncer, et qu'il faut garder en tête. Il n'y a aucune référence pré-IA — c'est une différence de taux sur douze semaines, pas un avant-après, donc « l'IA a ralenti les équipes » est une lecture plausible des données, pas une lecture démontrée. Et « 82 centimes de chaque dollar IA » est un modèle de l'endroit où part l'effort d'ingénierie lié à l'IA ; ce n'est pas 82 % de l'argent de votre entreprise parti en fumée. Le rapport inclut même les chiffres qui jouent contre sa propre alarme : 18 centimes atteignent bel et bien l'utilisateur, et ce taux d'approbation en moins d'une heure peut tout aussi bien signaler une équipe saine et bien outillée qu'une équipe négligente.
Alors je ne fais pas confiance au chiffre parce qu'un éditeur m'a dessiné un graphique. Je fais confiance à la forme — génération bon marché, vérification coûteuse, échec qui se compose — parce qu'elle colle à ce que je vois se produire en production chaque mois. (J'ai écrit ailleurs sur comment cette même forme a été tordue jusqu'à dire ce qu'elle ne dit pas en chemin vers un titre de Yahoo ; le cadrage est une leçon à lui seul.)
On a déjà vu ce film — c'est la facture cloud, un cran plus haut
Si cela vous semble familier, c'est normal. Quand le cloud a rendu le calcul bon marché, la dépense n'a pas chuté — elle s'est déplacée, elle a grossi, et on a passé une décennie à inventer le FinOps pour gouverner ce qu'on avait rendu facile à consommer. L'IA de codage, c'est ce même mouvement un cran plus haut dans la pile : elle a rendu la génération de code bon marché, et le coût s'est déplacé vers la vérification et l'exploitation. Les tokens sont la nouvelle ligne de dépense, et — comme je l'ai déjà soutenu — ils sont un coût à gouverner, pas une productivité à célébrer. L'ingénieur reste le multiplicateur. C'est juste la facture qui a changé d'adresse.
Ce que je ferais ce trimestre si j'étais votre CTO
Un diagnostic sans action n'est qu'une opinion. Cinq paris concrets :
- Mesurez le taux d'échec des changements, pas le volume. Les outils optimisent le nombre de PR ; l'entreprise paie pour le nombre de celles qui sont annulées. Mettez des métriques de résultat façon DORA sur le tableau de bord que votre direction lit vraiment, et surveillez le taux d'échec face à la vélocité, pas à sa place.
- Traitez les PR rédigées par l'IA comme leur propre classe de défauts. Étiquetez-les. Comparez leur taux d'annulation et la durée de vie de leurs bugs aux changements rédigés par des humains. On ne gère pas un risque qu'on refuse de séparer de la moyenne.
- Financez le harnais, pas seulement le générateur. Les 82 centimes sont la revue, la vérification et le retour de production. Dépensez là. Concrètement : bouclez votre propre boucle — réinjectez ce qui a réellement échoué et été annulé dans le contexte à partir duquel vos outils génèrent, pour que le prochain jet soit écrit depuis la réalité plutôt que depuis le dépôt.
- Comptez les ingénieurs vers le haut, pas vers le bas. Les équipes qui taillent dans les effectifs parce que « l'IA écrit le code maintenant » licencient les seules personnes qui rendent ce code vrai. Qui coupe le plus profond aujourd'hui passera 2027 à réembaucher — le travail réactif ne disparaît pas quand les relecteurs partent, il se livre simplement d'abord à vos utilisateurs.
- Gouvernez-la comme le cloud. Attribution des tokens par workflow, coupe-circuit sur chaque agent, et une couche de routage qui envoie les tâches triviales au modèle le moins cher qui suffit. Le coût qui dérape dans une organisation IA, ce n'est presque jamais un ingénieur bavard ; c'est un agent coincé dans une boucle de nouvelles tentatives.
La ligne que je trace
L'IA a rendu le premier jet gratuit. Elle n'a pas rendu gratuite la version livrée, vraie, survivante — elle l'a rendue plus précieuse, et il y en a plus à construire qu'il n'y en a jamais eu. Les 18 centimes qui atteignent vos utilisateurs, c'est la partie facile. Les 82 qui n'y arrivent pas, c'est là que vit réellement l'ingénierie, et prétendre qu'un outil a supprimé ce travail, c'est comme ça qu'on finit l'année à expliquer un taux d'annulation à son conseil.
Le modèle est devenu bon marché. Le jugement, non. Si votre stratégie IA confond les deux, vous n'avez pas une équipe plus rapide. Vous avez un plus grand nettoyage.
Vous voyez votre taux d'annulation grimper plus vite que votre vélocité depuis que vous avez déployé l'outillage IA ? Parlez à un CTO — nous vous aiderons à bâtir la couche de revue et de vérification qui transforme un premier jet plus rapide en quelque chose que vous pouvez réellement livrer.