La IA no abarató la ingeniería. Movió la factura aguas abajo.
Cualquier discurso de venta de una herramienta de IA para programar te promete lo mismo: velocidad. Escribe la funcionalidad en minutos, no en días. Entrega más con menos gente. Las demos son reales: el primer borrador llega de verdad en segundos.
Luego se cierra el trimestre, y la factura aparece en un sitio donde no estabas mirando.
Un nuevo estudio de Entelligence —un proveedor, y ahora vuelvo sobre eso— ha puesto número a dónde aparece. A lo largo de más de un millón de pull requests de 2.444 organizaciones de ingeniería, rastrearon dónde acaba realmente el esfuerzo de la ingeniería asistida por IA. El titular: por cada dólar que un equipo invierte en programar con IA, unos 18 céntimos se convierten en producto entregado. Los otros 82 se consumen antes de que una sola funcionalidad llegue a un usuario —gastados en arreglar, rehacer y revisar lo que generaron las herramientas.
No leo ese número desde la silla del inversor, ni desde la del proveedor. Lo leo desde la que llevo ocupando veinte años: la del que tiene que defender una línea de coste de IA ante un CFO y llevar la guardia que recoge lo que las herramientas dejaron en producción. Y desde esa silla, los 82 céntimos no son desperdicio. Son la parte del trabajo que no se automatizó, y son el mejor argumento que he visto este año para explicar por qué el ingeniero es la pieza que no puedes convertir en mercancía.
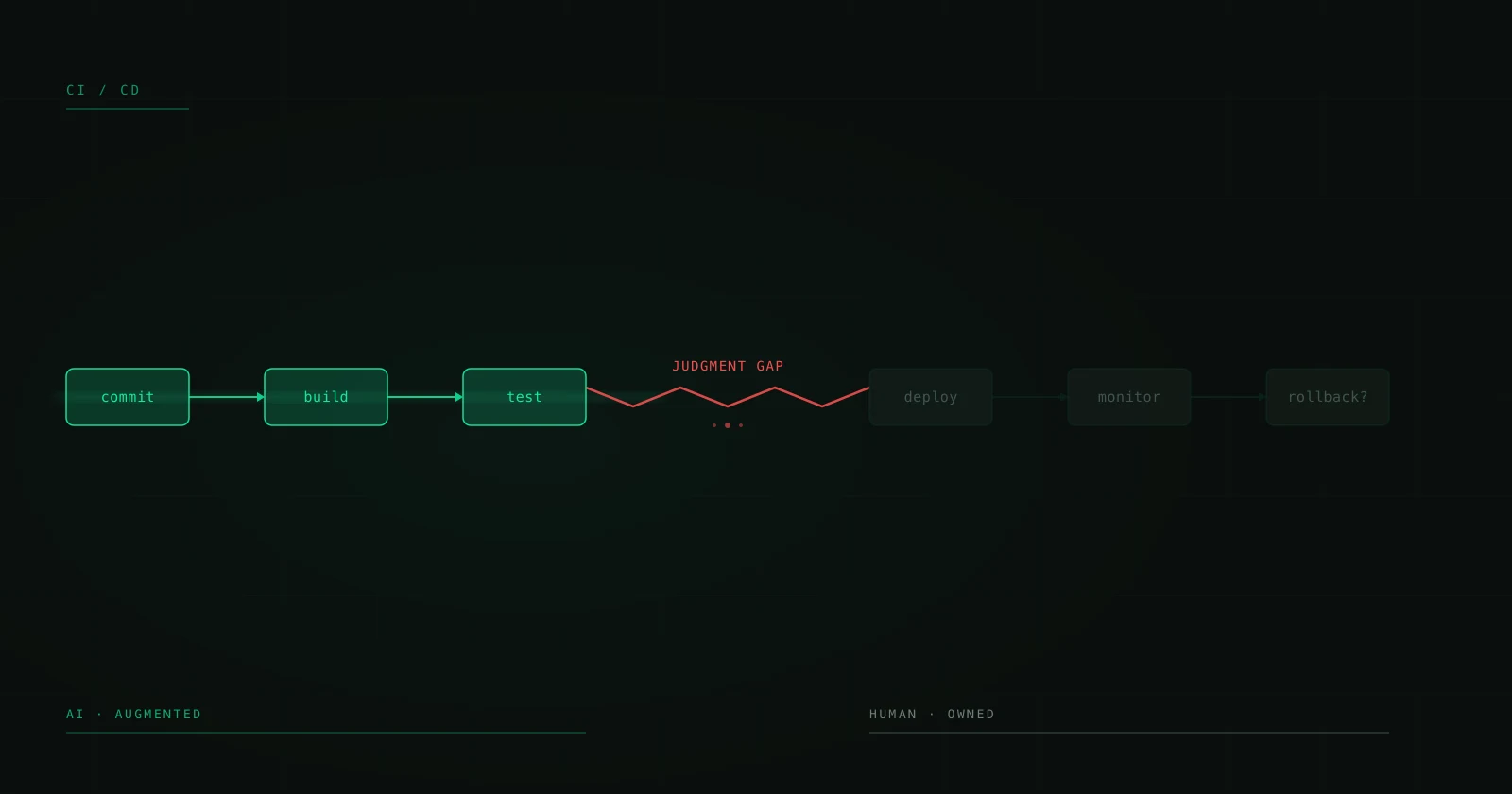
La IA abarató exactamente una cosa: el primer borrador
Quítale el marketing a un asistente de IA para programar y lo que vende es un primer borrador más rápido. Genera código plausible a partir del contexto local: el fichero en el que estás, la función de arriba, los patrones que ha visto un millón de veces. Eso tiene valor de verdad, y ahora es barato de verdad.
Lo que no puede hacer es saber cuál de esos patrones ya falló el mes pasado en tu producción. Escribe desde el repositorio, nunca desde la realidad: qué caso límite probaste y revertiste, qué reintento «obvio» tumbó el servicio de pagos en marzo, por qué ese null check que todo el mundo se empeña en borrar sostiene media aplicación. El modelo es el motor, y el motor se abarató —ya argumenté largo y tendido por qué un motor barato no es un coche barato—. Generar código siempre fue la parte fácil. Conseguir que el código generado sea verdad en producción es la parte difícil, y nada de un primer borrador más rápido lo hace más fácil.
Los 82 céntimos son la parte que solo tus ingenieros pueden hacer
Mira cómo el estudio descompone el dólar y el marco del «desperdicio» se cae solo. De esos 82 céntimos: unos 44 se van en trabajo reactivo —arreglar errores y mantener los sistemas en pie—, 27 en rehacer código que no sobrevivió al contacto con la realidad, y 11 en revisión. Cada uno de ellos es una decisión de criterio que ocurre aguas abajo de la generación. Cada uno es el trabajo de decidir si lo plausible que escribió el modelo es lo correcto para entregar.
Ese dólar no se evaporó. Se trasladó —de teclear el código a verificarlo, integrarlo y operarlo—. Es el mismo movimiento al que no paro de apuntar: el valor sube por el stack, de la capa que el modelo te puede dar a la capa que no. Cuanto más se abarata la generación, más se concentra tu dólar en la parte que necesita a un humano que ya ha entregado antes. Llámalo la cuota de trabajo reactivo, y en la organización mediana de este conjunto de datos es el 44% de toda la capacidad de ingeniería, antes de contar la cola larga donde pasa de las tres cuartas partes.
Los reverts crecen más rápido que el trabajo que los crea
Aquí está el número que debería preocupar a un CTO más que los 82 céntimos. A lo largo de doce semanas, el estudio vio el volumen semanal de pull requests subir 2,6×, y los PR revertidos subir 3,7×. El fallo se acumula más rápido que la producción. No solo entregas más: entregas más que luego hay que retirar.
El mecanismo no tiene misterio, y no es que los ingenieros hayan empeorado. Es que la capa de revisión nunca escaló con el volumen. Cuando multiplicas por 2,6 la entrada a un proceso de verificación sin hacer crecer la verificación, la tasa de fugas sube por definición. El propio informe lo enseña sin rodeos: casi la mitad de los PR se aprueban en menos de una hora, la mayoría de los comentarios de revisión son ruido generado por bots, y solo en torno a una quinta parte de los comentarios llega a aplicarse alguna vez. Una de cada cuatro líneas escritas cada semana se descarta dentro de esa misma semana. Puedes generar código a velocidad de máquina. No puedes revisarlo a velocidad de máquina y seguir llamándolo revisión, y el hueco entre esas dos velocidades es exactamente de donde salen los reverts.
Este número es de un proveedor, y aun así me fío de su forma
Ahora la parte que casi toda la cobertura se saltó. Entelligence vende la cura. Su producto cierra «el bucle entre el código y la producción» —que es, qué casualidad, justo lo que el informe concluye que te falta—. Cuando quien vende un número sale ganando con tu alarma, descuéntalo. Siempre.
Dos salvedades más que el informe es lo bastante honesto para reconocer, y a las que conviene agarrarse. No hay línea base previa a la IA: esto es una diferencia de ritmo a lo largo de doce semanas, no un antes y un después, así que «la IA volvió más lentos a los equipos» es una lectura plausible de los datos, no algo demostrado. Y «82 céntimos de cada dólar de IA» es un modelo de adónde va el esfuerzo de ingeniería con IA; no es el 82% del dinero de tu empresa quemado. El informe incluye incluso las cifras que juegan en contra de su propia alarma: 18 céntimos sí llegan al usuario, y esa tasa de aprobación en menos de una hora puede ser señal de un equipo sano y bien equipado tanto como de uno negligente.
Así que no me fío del número porque un proveedor me haya dibujado un gráfico. Me fío de la forma —generación barata, verificación cara, fallo que se acumula— porque coincide con lo que veo pasar en producción cada mes. (Escribí aparte sobre cómo esa misma forma se retorció hasta decir algo que no dice de camino a un titular de Yahoo; el encuadre es una lección en sí mismo.)
Esta película ya la hemos visto: es la factura del cloud, una capa más arriba
Si esto te suena, debería. Cuando el cloud abarató la computación, el gasto no bajó: se movió, y creció, y nos pasamos una década inventando FinOps para gobernar lo que habíamos vuelto fácil de consumir. Programar con IA es ese mismo movimiento una capa más arriba del stack: abarató generar código, y el coste se trasladó a verificarlo y operarlo. Los tokens son la nueva línea de gasto y —como ya he defendido antes— son un coste que gobernar, no una productividad que celebrar. El ingeniero sigue siendo el multiplicador. La factura solo ha cambiado de dirección.
Qué haría este trimestre si fuera tu CTO
Un diagnóstico sin acción no es más que una opinión. Cinco apuestas concretas:
- Mide la tasa de fallo del cambio, no el volumen. Las herramientas optimizan el número de PR; el negocio paga por el número que se revierte. Pon métricas de resultado tipo DORA en el panel que tu dirección lee de verdad, y vigila la tasa de fallo frente a la velocidad, no en lugar de ella.
- Trata los PR escritos por IA como su propia clase de defecto. Etiquétalos. Compara su tasa de revert y cuánto viven sus errores frente a los cambios escritos por humanos. No puedes gestionar un riesgo que te niegas a separar de la media.
- Financia el arnés, no solo el generador. Los 82 céntimos son revisión, verificación y feedback de producción. Gasta ahí. En concreto: cierra tu propio bucle —devuelve lo que de verdad falló y se revirtió al contexto desde el que generan tus herramientas, para que el siguiente borrador se escriba desde la realidad y no desde el repo—.
- Suma ingenieros, no los restes. Los equipos que recortan plantilla porque «ahora la IA escribe el código» están despidiendo a la única gente capaz de hacer que ese código sea verdad. Quien recorte más hondo hoy se pasará 2027 recontratando: el trabajo reactivo no desaparece cuando se van los revisores, simplemente llega antes a tus usuarios.
- Gobiérnalo como el cloud. Atribución de tokens por flujo de trabajo, un interruptor de emergencia en cada agente, y una capa de enrutado que mande las tareas triviales al modelo más barato que baste. El coste desbocado en una organización de IA rara vez es un ingeniero charlando de más con el modelo; es un agente atascado en un bucle de reintentos.
Dónde trazo la raya
La IA hizo gratis el primer borrador. No hizo gratis la versión entregada, verdadera y que sobrevive: la hizo más valiosa, y hay más de ella por construir que nunca. Los 18 céntimos que llegan a tus usuarios son la parte fácil. Los 82 que no llegan son donde vive de verdad la ingeniería, y fingir que una herramienta eliminó ese trabajo es la forma de terminar el año explicándole a tu consejo una tasa de revert.
El modelo se abarató. El criterio no. Si tu estrategia de IA confunde esas dos cosas, no tienes un equipo más rápido. Tienes una limpieza más grande.
¿Ves tu tasa de revert subir más rápido que tu velocidad desde que desplegaste herramientas de IA? Habla con un CTO: te ayudamos a construir la capa de revisión y verificación que convierte un primer borrador más rápido en algo que de verdad puedas entregar.