AI Didn't Make Engineering Cheaper. It Moved the Bill Downstream.
Every pitch for an AI coding tool sells you the same thing: speed. Write the feature in minutes, not days. Ship more with fewer people. The demos are real — the first draft genuinely does arrive in seconds.
Then the quarter closes, and the bill shows up somewhere you weren't looking.
A new study from Entelligence — a vendor, and I'll come back to that — put a number on where it shows up. Across more than a million pull requests from 2,444 engineering organizations, they tracked where AI-assisted engineering effort actually lands. The headline finding: for every dollar a team spends on AI coding, about 18 cents becomes shipped product. The other 82 are consumed before a single feature reaches a user — spent fixing, reworking, and reviewing what the tools generated.
I'm not reading that number from the investor's seat, or the vendor's. I'm reading it from the one I've occupied for twenty years: the person who has to defend an AI cost line to a CFO and run the on-call rotation that catches what the tools shipped. And from that seat, the 82 cents isn't waste. It's the part of the job that didn't get automated — and it's the strongest argument I've seen this year for why the engineer is the part you can't commoditize.
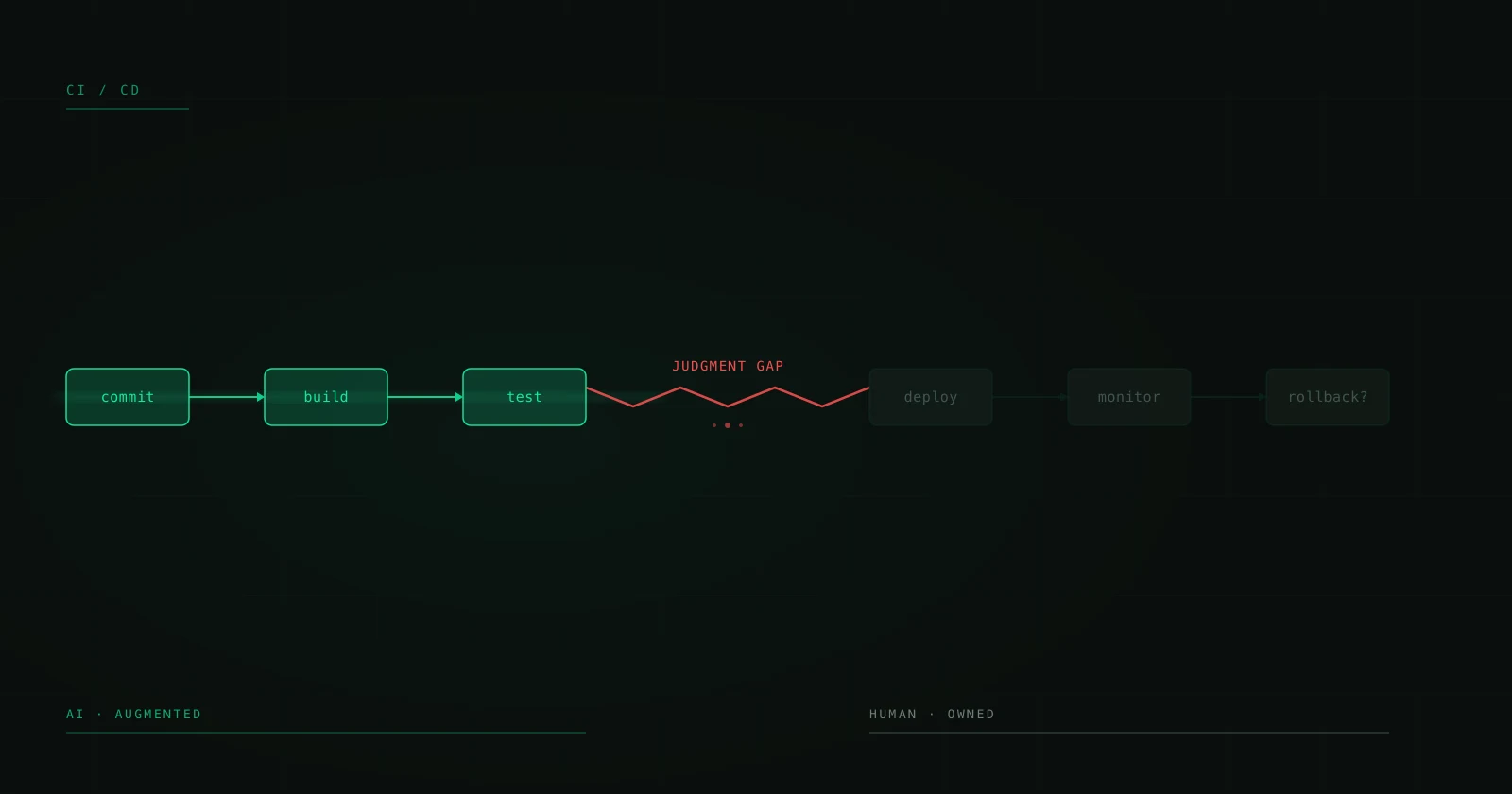
AI made exactly one thing cheap: the first draft
Strip the marketing off an AI coding assistant and what it sells is a faster first draft. It generates plausible code from local context — the file you're in, the function above, the patterns it has seen a million times. That is genuinely valuable, and it is genuinely cheap now.
What it cannot do is know which of those patterns already failed in your production last month. It writes from the repository, never from reality: which edge case you tried and reverted, which "obvious" retry took down the payment service in March, why that null check everyone keeps deleting is load-bearing. The model is the engine, and the engine got cheap — I argued at length why a cheap engine is not a cheap car. Generating code was always the easy part. Making generated code true in production is the hard part, and nothing about a faster first draft makes it easier.
The 82 cents is the part only your engineers can do
Look at how the study breaks the dollar down, and the framing of "waste" falls apart. Of that 82 cents: roughly 44 go to reactive work — fixing bugs and keeping systems running — 27 to reworking code that didn't survive contact with reality, and 11 to review. Every one of those is a judgment call downstream of generation. Every one is the work of deciding whether the plausible thing the model wrote is the correct thing to ship.
That dollar didn't vanish. It relocated — from typing the code to verifying it, integrating it, and operating it. This is the same move I keep pointing at: value climbs the stack, from the layer the model can hand you to the layer it can't. The cheaper generation gets, the more of your dollar concentrates in the part that needs a human who has shipped before. Call it the reactive-work share — and at the median organization in this dataset, it's 44% of all engineering capacity, before you count the long tail where it passes three-quarters.
Reverts are growing faster than the work that creates them
Here is the number that should worry a CTO more than the 82 cents. Over twelve weeks, the study tracked weekly pull-request volume climbing 2.6× — and reverted PRs climbing 3.7×. Failure is compounding faster than output. You are not just shipping more; you are shipping more that has to be pulled back.
The mechanism is not mysterious, and it isn't that engineers got worse. It's that the review layer never scaled with the volume. When you multiply the input to a verification process 2.6× without growing the verification, the escape rate climbs by definition. The same report shows it plainly: nearly half of PRs are approved in under an hour, most review comments are bot-generated noise, and only about a fifth of comments are ever acted on. One in four lines written each week is discarded within that same week. You can generate code at machine speed. You cannot review it at machine speed and still call it review — and the gap between those two speeds is exactly where the reverts come from.
This is a vendor's number — here's why I still trust the shape
Now the part most coverage skipped. Entelligence sells the cure. Their product closes "the loop between code and production" — which is, conveniently, the exact thing the report concludes you're missing. When a number's seller profits from your alarm, discount it. Always.
Two more caveats the report is honest enough to state, and you should hold onto. There is no pre-AI baseline — this is a rate difference over twelve weeks, not a before-and-after, so "AI made teams slower" is a plausible reading of the data, not a proven one. And "82 cents of every AI dollar" is a model of where AI-engineering effort goes; it is not 82% of your company's money set on fire. The report even includes the figures that cut against its own alarm: 18 cents does reach users, and that sub-hour approval rate can be a sign of a healthy, well-tooled team as easily as a negligent one.
So I don't trust the number because a vendor drew me a chart. I trust the shape — generation cheap, verification expensive, failure compounding — because it matches what I watch happen in production every month. (I wrote separately about how that same shape got bent into something it doesn't say on its way to a Yahoo headline; the framing is its own lesson.)
We've seen this movie — it's the cloud bill, one layer up
If this feels familiar, it should. When the cloud made compute cheap, the spend didn't fall — it moved, and it grew, and we spent a decade inventing FinOps to govern what we'd made easy to consume. AI coding is that same move one layer up the stack: it made generating code cheap, and the cost relocated to verifying and operating it. Tokens are the new line item, and — as I've argued before — they're a cost to govern, not a productivity to celebrate. The engineer is still the multiplier. The bill just changed address.
What I'd do this quarter if I were your CTO
A diagnosis without action is just an opinion. Five concrete bets:
- Measure change-failure-rate, not volume. The tools optimize for the number of PRs; the business pays for the number that get reverted. Put DORA-style outcome metrics on the dashboard your leadership actually reads, and watch the failure rate against the velocity, not instead of it.
- Treat AI-authored PRs as their own defect class. Tag them. Compare their revert rate and bug lifetime to human-authored changes. You cannot manage a risk you refuse to separate from the average.
- Fund the harness, not just the generator. The 82 cents is review, verification, and production feedback. Spend there. Concretely: close your own loop — feed what actually failed and reverted back into the context your tools generate from, so the next draft is written from reality instead of from the repo.
- Count engineers up, not down. The teams cutting headcount because "AI writes the code now" are firing the only people who make the code true. Whoever cuts deepest today spends 2027 rehiring — the reactive work doesn't disappear when the reviewers do, it just ships to your users first.
- Govern it like cloud. Per-workflow token attribution, a kill-switch on every agent, and a routing layer that sends trivial tasks to the cheapest sufficient model. The runaway cost in an AI org is rarely a chatty engineer; it's an agent in a retry loop.
The line I'm drawing
AI made the first draft free. It did not make the shipped, true, surviving version free — it made that version more valuable, and there is more of it to build than there has ever been. The 18 cents that reaches your users is the easy part. The 82 that don't are where the engineering actually lives, and pretending a tool removed that work is how you end the year explaining a revert rate to your board.
The model got cheap. The judgment didn't. If your AI strategy confuses those two, you don't have a faster team. You have a bigger cleanup.
Watching your revert rate climb faster than your velocity since you rolled out AI tooling? Talk to a CTO — we'll help you build the review-and-verification layer that turns a faster first draft into something you can actually ship.