Book Review: \"Accelerate\" — The Science Behind DevOps and High-Performing Teams
Most books about software engineering are opinion dressed up as advice. "Accelerate: The Science of Lean Software and DevOps" by Nicole Forsgren, Jez Humble, and Gene Kim is not one of those books. Published in 2018, it's built on four years of rigorous statistical research through the State of DevOps Reports, surveying tens of thousands of professionals. The claims are backed by data, not anecdotes.
If you lead an engineering team and haven't read this book, stop reading this review and go buy it. Then come back. I'm serious -- it's the single most useful book I've recommended to every engineering leader I work with.
The core thesis: how you ship predicts how the business performs
The book's central argument is simple and powerful: software delivery performance predicts organizational performance. Teams that deliver software faster, with higher quality, also work in organizations that are more profitable, have higher market share, and achieve better employee satisfaction.
This isn't correlation masquerading as causation. Forsgren's team used cluster analysis and structural equation modeling to establish predictive relationships. High-performing teams don't just happen to be at successful companies. Their engineering practices directly contribute to business outcomes.
That matters because it gives you ammunition. The next time someone in the C-suite asks why you need to invest in CI/CD or reduce deployment friction, you have peer-reviewed research to back you up.
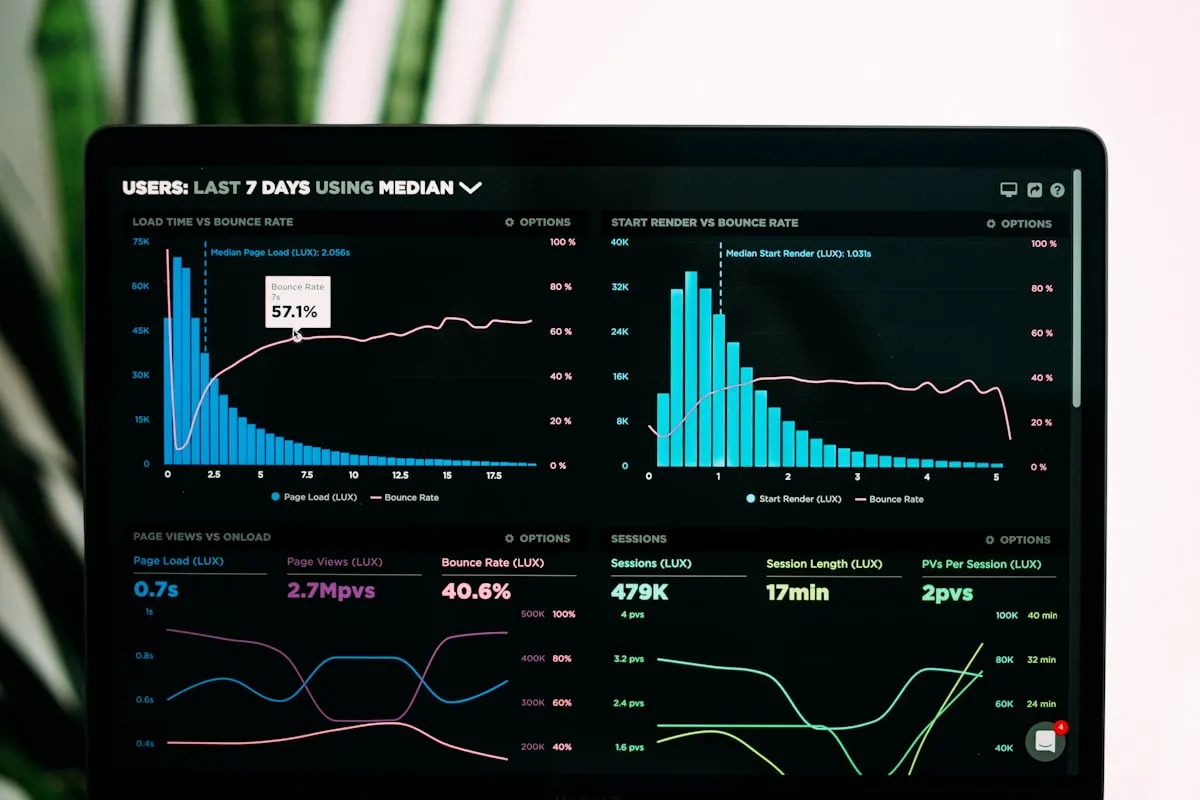
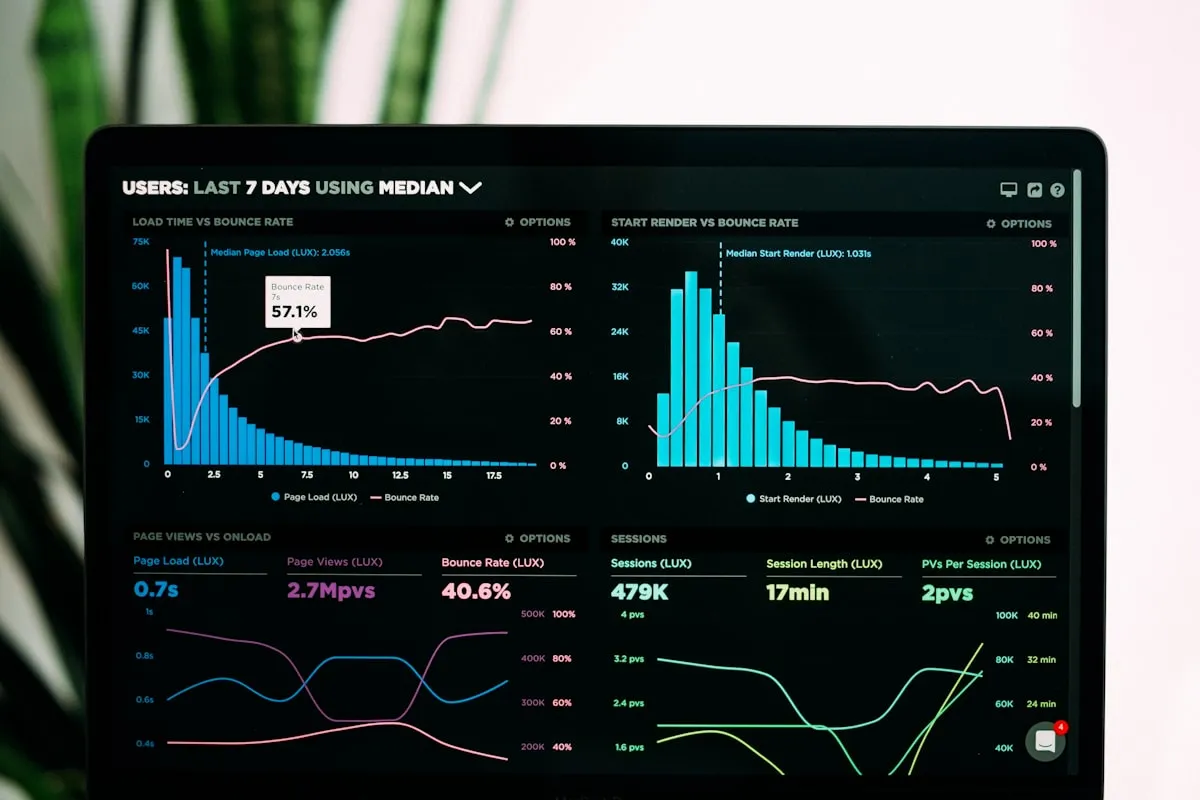
The four DORA metrics: speed and stability are not a trade-off
The book defines four metrics that reliably distinguish high performers from low performers. These have since become industry standard as the DORA metrics (DevOps Research and Assessment):
-
Deployment frequency. How often your team deploys to production. High performers deploy on demand, multiple times per day. Low performers deploy between once per month and once every six months.
-
Lead time for changes. The time from code commit to running in production. High performers measure this in under an hour. Low performers take between one month and six months.
-
Mean time to restore (MTTR). When something breaks in production, how long does it take to recover? High performers: under an hour. Low performers: between one week and one month.
-
Change failure rate. What percentage of deployments cause a failure in production? High performers: 0-15%. Low performers: 46-60%.
What's remarkable is how these metrics reinforce each other. Teams that deploy more frequently have lower change failure rates, not higher. Smaller, more frequent releases are inherently safer than big-bang deployments. This is counterintuitive to managers who think slower = safer, and the data demolishes that assumption.
The 24 capabilities: a diagnosis you can act on
Beyond the metrics, the book identifies 24 capabilities grouped into five categories that drive software delivery performance:
Continuous delivery capabilities
- Version control for all production artifacts
- Automated deployment processes
- Continuous integration
- Trunk-based development
- Test automation
- Test data management
- Shift left on security
- Loosely coupled architecture
Architecture capabilities
- Teams can deploy independently without coordination
- Teams can test independently
- Loosely coupled, well-encapsulated systems
Product and process capabilities
- Customer feedback loops
- Value stream visibility
- Working in small batches
- Team experimentation
Lean management and monitoring
- Lightweight change approval processes
- Monitoring and observability
- Proactive failure notification
- WIP limits
Cultural capabilities
- Westrum organizational culture (generative vs. pathological)
- Learning culture
- Collaboration across teams
- Job satisfaction
- Transformational leadership
The beauty of this framework is that it's actionable. You can assess your team against each capability and identify concrete areas for improvement. It turns "we need to get better" into "we need to improve our test automation and move toward trunk-based development."
How to run your own capability assessment
This is where the book becomes a practical tool, not just an interesting read. Here's how I've used it:
-
Rate each capability on a 1-5 scale. Have your team do this independently, then compare. The gaps between how leadership perceives a capability and how individual contributors perceive it are often the most revealing finding.
-
Identify your bottlenecks. You don't need to be a 5 on everything. Find the capabilities where you score lowest and that have the highest leverage on your delivery metrics. Usually that's CI/CD automation, test coverage, and deployment frequency.
-
Set quarterly improvement targets. Pick 2-3 capabilities per quarter. Define what a one-point improvement looks like concretely. "Move from manual deployments to automated staging deploys" is a capability improvement you can measure.
-
Measure the DORA metrics before and after. The metrics give you an objective way to verify whether your capability improvements are actually moving the needle.
I've seen teams go from deploying weekly to deploying daily within a quarter by focusing specifically on their CI pipeline and deployment automation. The improvement in developer confidence alone is worth the investment.
What's aged well after five years
The DORA metrics are now industry standard. Google adopted them, built the DORA team, and publishes annual State of DevOps reports that continue validating and extending the original research. The metrics are embedded in tools like Sleuth, LinearB, and Jellyfish. When I talk to other CTOs, DORA metrics are the common language we use.
The cultural findings are more relevant than ever. The emphasis on Westrum's generative culture -- high trust, information flow, shared responsibilities, novelty welcomed -- has only become more important as distributed teams became the norm post-2020. Pathological organizations (power-oriented, low cooperation, failure leads to punishment) cannot sustain high performance regardless of their tooling. I've seen this play out dozens of times.
Trunk-based development has won. The book advocated for it when many teams were still doing long-lived feature branches. Today, the industry has largely moved toward short-lived branches and frequent merges, and the data continues to support this approach.
Architecture matters more than tools. The finding that loosely coupled architectures enable high performance independent of specific technology choices remains true. Teams that can deploy independently outperform those that can't, regardless of whether they use Kubernetes or Heroku.
What hasn't aged as well
The pace categories are outdated. The original "elite, high, medium, low" performer classifications had specific numeric thresholds that no longer reflect industry reality. Deployment frequency expectations have shifted dramatically. What was "elite" in 2018 is table stakes for many teams today.
Cloud native is assumed, not aspirational. The book spent significant effort arguing for cloud infrastructure and automated provisioning. In 2023, this is default for most startups. The frontier has moved to developer experience, platform engineering, and internal developer platforms.
The treatment of microservices is thin. The architecture section correctly identifies loose coupling as critical but doesn't deeply address the operational complexity that microservices introduce. The industry has since learned -- sometimes painfully -- that distributed systems come with their own category of problems.
Security has become a bigger concern. "Shift left on security" was one capability among 24. Today, with supply chain attacks, dependency vulnerabilities, and regulatory requirements, it deserves an entire book of its own.
The bottom line
"Accelerate" gave the industry something it desperately needed: evidence-based answers to questions we'd been debating with opinions for decades. Does continuous delivery actually help? (Yes.) Does culture matter? (More than tools.) Can you deploy faster without sacrificing quality? (Yes -- the two are correlated, not opposed.)
Five years later, the core findings haven't just held up -- they've become the foundation for how serious engineering organizations measure themselves. If you're leading a team and making decisions about process, tooling, and culture without having read this book, you're operating without a map.
At Conectia, the DORA metrics are part of how we evaluate engineering maturity when we work with clients. Our senior LATAM engineers have built the capabilities this book describes -- CI/CD pipelines, automated testing, trunk-based workflows -- because those are the practices the book's data keeps rewarding.
Read the book. Assess your team. Pick the two capabilities that will move the needle most. Start there.
Building a team that can actually deliver on the capabilities Accelerate describes? Talk to a CTO.