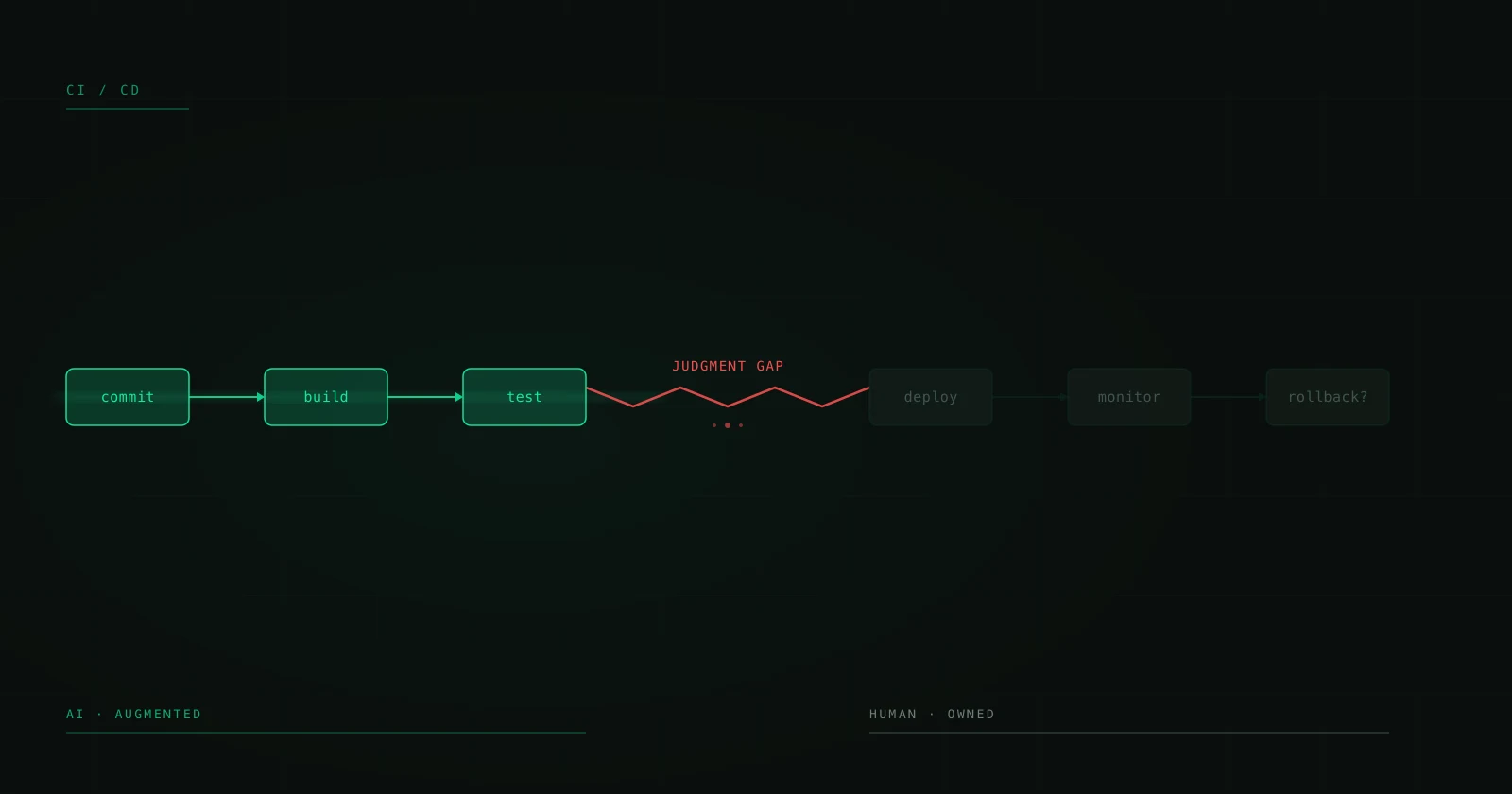
Human in the Loop: Porque é que as Melhores Implementações de IA Não Eliminam o Humano
Há uma narrativa perigosa no ecossistema de IA: que o objetivo é eliminar o humano do processo. Automatização total. End-to-end AI. Zero-touch workflows. Soa espetacular num pitch deck. Em produção, é a receita para desastres silenciosos que escalam mais depressa do que qualquer bug que já tenhas visto.
Os sistemas de IA que realmente funcionam em produção — os que processam milhares de transações por dia sem provocar crises — têm algo em comum: mantêm um humano no loop. Não por limitação técnica, mas por design. Porque há decisões que um modelo não deve tomar sozinho, contextos que não consegue avaliar, e erros que não consegue detetar em si próprio.
Isto não é um artigo sobre porque é que a IA não está pronta. Está mais do que pronta. Isto é sobre como desenhar sistemas onde a IA faz o trabalho pesado e o humano intervém exatamente onde acrescenta mais valor.
O problema da automatização cega
Um LLM consegue classificar um email de suporte com 95% de precisão. Parece um número excelente. Até fazeres as contas: se recebes 1.000 emails por dia, 50 estão mal classificados. Se a classificação dispara ações automáticas — enviar um reembolso, escalar para o jurídico, fechar um ticket — esses 50 erros diários não são uma percentagem estatística. São 50 clientes com uma experiência comprometida.
O problema agrava-se com a confiança. Um modelo que se engana e sabe que se enganou é gerível. Um modelo que se engana com alta confiança é perigoso. Os LLMs são particularmente propensos a isto: geram respostas coerentes e bem redigidas que parecem corretas mesmo quando não o são. As famosas alucinações não vêm com um rótulo de aviso.
A automatização cega amplifica erros à velocidade de máquina. Um humano que comete um erro processa talvez 100 casos por dia. Um pipeline automático com defeito processa 10.000 antes de alguém se aperceber.
Os três padrões de Human in the Loop
Não existe um único modelo de HITL. Há três padrões fundamentais, e escolher o correto depende do teu caso de uso, da tua tolerância ao risco e do custo de um erro.
Padrão 1: Human-as-Validator (revisão antes da ação)
A IA processa, classifica, gera ou extrai. O humano revê e aprova antes de a ação ser executada. É o padrão mais conservador e o que deves usar por defeito quando o custo de um erro é elevado.
Quando usar:
- Processamento de documentos financeiros ou jurídicos
- Geração de respostas a clientes em contextos sensíveis
- Decisões que envolvem dinheiro (reembolsos, aprovações de crédito)
- Qualquer output que é enviado para fora da tua organização
Arquitetura típica:
Input → Modelo IA → Fila de revisão → Humano aprova/rejeita → Ação
↓
Feedback ao modelo
A chave está na fila de revisão. Não é um simples "sim/não". Um bom sistema de validação mostra ao humano: o input original, o output do modelo, o score de confiança, e os fragmentos de contexto que o modelo usou para tomar a decisão. O humano não revê do zero — valida o trabalho da IA. Isso é 10x mais rápido do que fazer o trabalho manualmente.
Padrão 2: Human-as-Exception-Handler (intervenção por exceção)
A IA processa a maioria dos casos automaticamente. Só escala para o humano quando deteta que não consegue resolver o caso com confiança suficiente, ou quando o caso está fora dos parâmetros definidos.
Quando usar:
- Alto volume, baixo risco por caso individual
- Suporte tier 1 (chatbots com escalação)
- Classificação de conteúdo
- Processamento de documentos estandardizados
Arquitetura típica:
Input → Modelo IA → Confiança > limiar?
↓ Sim ↓ Não
Ação auto → Humano resolve
↓
Feedback ao modelo
O limiar de confiança é a tua alavanca principal. Demasiado alto: demasiados casos escalam e perdes o benefício da automatização. Demasiado baixo: passam erros que destroem a confiança do utilizador. A calibração é empírica — começas conservador (limiar alto) e baixas gradualmente enquanto monitorizas a taxa de erros nos casos automáticos.
Um bom sistema de exception handling precisa de routing inteligente. Não é a mesma coisa um caso que o modelo não compreende (precisa de um especialista de domínio) e um caso onde o modelo compreende mas o risco é elevado (precisa de um supervisor). Desenha as tuas filas de escalação com esta distinção.
Padrão 3: Human-as-Teacher (feedback loop contínuo)
O humano não está no fluxo operativo direto. Em vez disso, revê periodicamente uma amostra dos outputs automáticos, etiqueta erros, e essa informação é usada para melhorar o modelo ou ajustar os prompts.
Quando usar:
- Sistemas já maduros com baixa taxa de erro
- Casos onde a latência de revisão não é aceitável
- Domínios onde o contexto muda gradualmente (drift)
Arquitetura típica:
Input → Modelo IA → Ação auto (100%)
↓
Amostra aleatória (5-10%)
↓
Revisão periódica → Ajuste de prompts / fine-tuning
Este padrão requer maturidade. Não o implementes desde o dia 1. Começa com Human-as-Validator ou Exception-Handler, e migra para Teacher quando tiveres dados suficientes para demonstrar que a taxa de erro é consistentemente baixa.
Desenhar o handoff: onde a maioria falha
O ponto de transferência entre IA e humano é onde a maioria das implementações se parte. Não por causa da IA nem do humano, mas pela interface entre ambos.
Erros comuns:
-
Context loss: O humano recebe um caso escalado sem contexto. Tem de começar do zero, investigar o que aconteceu, perceber porque é que a IA o escalou. Solução: passa TODO o contexto — input original, raciocínio do modelo, tentativas anteriores, histórico do utilizador.
-
Alert fatigue: Se 40% dos casos são escalados, os humanos começam a aprovar em modo automático sem rever. É pior do que não ter HITL, porque cria uma falsa sensação de segurança. Solução: mantém a taxa de escalação abaixo dos 15-20%. Se for mais alta, o teu modelo precisa de melhorias, não de mais humanos.
-
Feedback loop partido: O humano corrige erros mas essa correção não volta ao sistema. O mesmo erro repete-se indefinidamente. Solução: cada correção humana é um dado de treino. Captura a decisão, o raciocínio, e realimenta o pipeline de melhoria.
-
Latência inaceitável: O caso espera na fila de revisão 4 horas. Nessa altura o cliente já se foi embora. Solução: define SLAs por tipo de caso e prioridade. Os casos urgentes vão para uma fila fast-track com alertas.
Métricas que importam num sistema HITL
Não meças apenas a precisão do modelo. Mede o sistema completo:
-
Throughput efetivo: Casos resolvidos por hora incluindo o tempo humano. Se a tua IA processa 1.000 casos/hora mas escala 300 que demoram 15 minutos cada, o teu throughput real é muito diferente do teórico.
-
Taxa de escalação: Percentagem de casos que requerem intervenção humana. Deve baixar com o tempo se o teu feedback loop funcionar.
-
Tempo de resolução humana: Quanto tempo demora o humano a resolver um caso escalado. Se é quase igual ao tempo sem IA, o teu sistema de contexto está a falhar.
-
Taxa de override: Com que frequência o humano altera a decisão da IA. Se for muito alta (>30%), o teu modelo precisa de trabalho. Se for muito baixa (<2%), provavelmente estás a escalar demasiados casos que não o necessitam.
-
Error rate pós-validação: Erros que passaram a revisão humana. Sim, os humanos também cometem erros. Um bom sistema HITL reconhece isto e tem checks downstream.
Quando NÃO precisas de HITL
Nem tudo precisa de um humano no loop. Há contextos onde a automatização total é correta:
-
Tarefas internas de baixo risco: Resumir reuniões, classificar documentos internos, gerar rascunhos. Se o erro não tem consequências externas, automatiza sem medo.
-
Sistemas com rollback fácil: Se consegues desfazer a ação automaticamente quando detetas um erro, a consequência do erro é baixa.
-
Processamento idempotente: Se processar algo duas vezes (uma automática incorreta + uma correção) não tem custo significativo.
A regra geral: se o erro chega ao cliente, ao regulador, ou a uma conta bancária, põe um humano. Se o erro fica interno e é corrigível, automatiza.
Implementação prática: stack técnico
Um sistema HITL não requer infraestrutura exótica. Os componentes básicos:
-
Fila de mensagens (SQS, RabbitMQ, Redis Streams): Para o buffer entre IA e humano. Os casos esperam aqui com o seu contexto.
-
Dashboard de revisão: Uma interface onde o humano vê o caso, o output da IA, e pode aprovar, rejeitar ou editar. Pode ser tão simples como uma app React com um backend que lê da fila.
-
Sistema de logging: Cada decisão — automática ou humana — fica registada. Input, output, confiança do modelo, decisão humana, timestamp. Isto é o teu dataset de melhoria.
-
Pipeline de feedback: Um processo periódico (diário, semanal) que pega nas correções humanas e as converte em melhorias — ajustes de prompts, exemplos de few-shot, ou dados de fine-tuning.
-
Alertas e monitorização: Se a taxa de escalação sobe 20% numa hora, algo mudou. Se o tempo médio de resolução humana duplica, a fila está saturada. Precisas de saber isto em tempo real.
O humano certo no loop
Nem qualquer humano serve. A pessoa que revê outputs de IA precisa de:
- Conhecimento de domínio: Compreender o contexto do caso para avaliar se o output está correto.
- Calibração: Saber quando a IA costuma falhar e onde prestar mais atenção.
- Disciplina: Não cair na tentação de aprovar tudo quando a fila cresce.
O perfil ideal é alguém que fazia este trabalho manualmente antes da IA. Conhece os edge cases, sabe o que pode correr mal, e consegue detetar erros que alguém sem experiência deixaria passar.
Da demo à produção
A diferença entre uma demo de IA e um sistema em produção é precisamente isto: a gestão de erros, a escalação, o feedback loop, a monitorização. A IA é 30% do sistema. Os outros 70% são a engenharia à volta — e o human in the loop é a peça central dessa engenharia.
Não é uma limitação temporária que desaparecerá quando os modelos forem melhores. É um padrão de design fundamental para sistemas que operam no mundo real, onde os erros têm consequências e a confiança se constrói com cada interação correta.
Constrói para que a IA faça 80% do trabalho. Desenha para que o humano contribua com os 20% de julgamento que transformam um sistema impressionante num sistema fiável.
Estás a desenhar um sistema de IA que precisa de funcionar em produção, não apenas numa demo? Fala com um CTO — os nossos engenheiros já implementaram pipelines HITL em produção para empresas reais.