Human in the Loop: Perché le Migliori Implementazioni di IA Non Eliminano l'Essere Umano
C'è una narrativa pericolosa nell'ecosistema dell'IA: che l'obiettivo sia eliminare l'essere umano dal processo. Automazione totale. End-to-end AI. Zero-touch workflows. Suona spettacolare in un pitch deck. In produzione, è la ricetta per disastri silenziosi che scalano più velocemente di qualsiasi bug tu abbia mai visto.
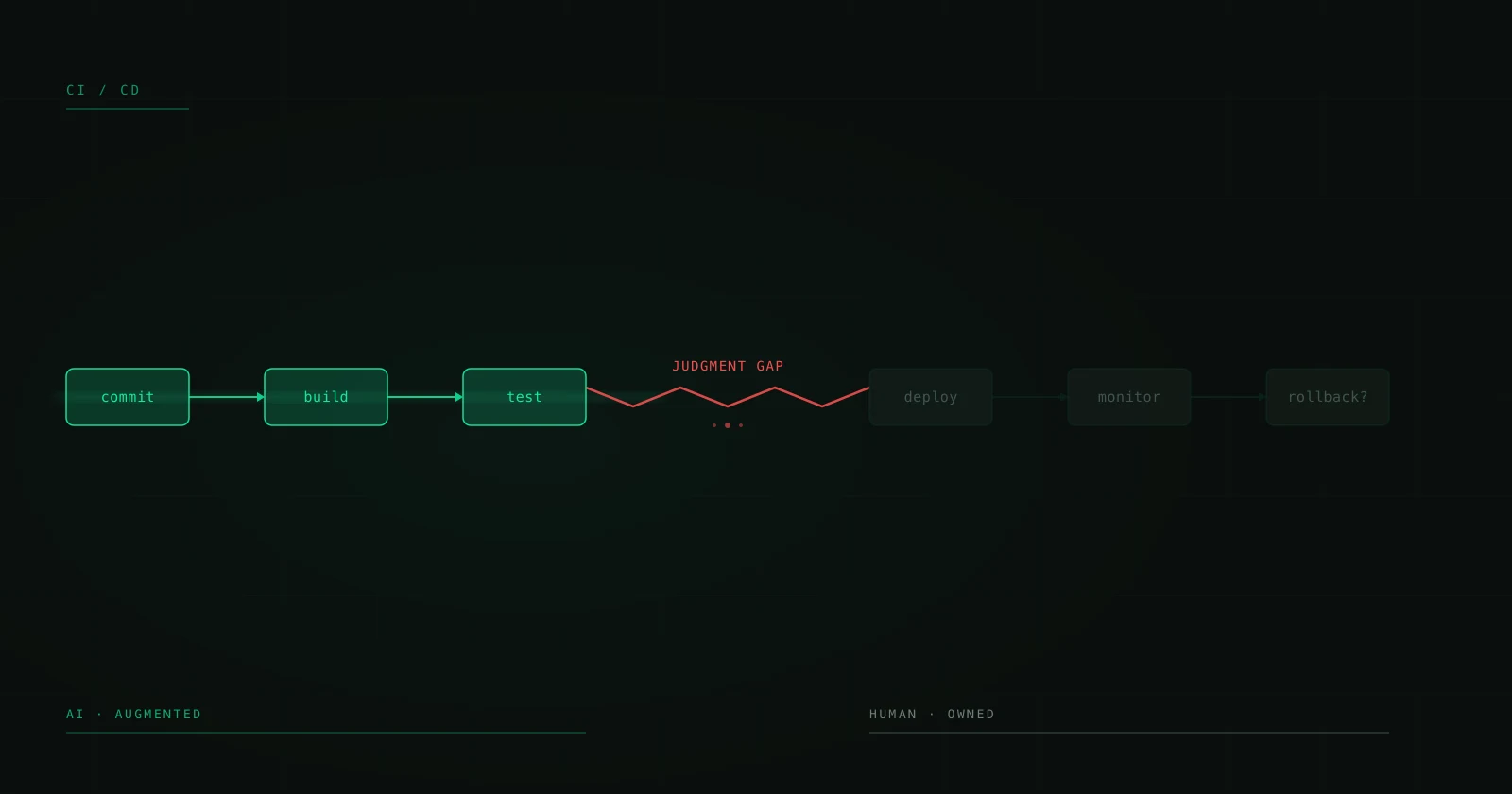
I sistemi di IA che funzionano davvero in produzione — quelli che elaborano migliaia di transazioni al giorno senza provocare crisi — hanno qualcosa in comune: mantengono un essere umano nel loop. Non per limitazione tecnica, ma per design. Perché ci sono decisioni che un modello non dovrebbe prendere da solo, contesti che non può valutare, ed errori che non può rilevare in sé stesso.
Questo non è un articolo sul perché l'IA non sia pronta. È più che pronta. Questo articolo parla di come progettare sistemi in cui l'IA fa il lavoro pesante e l'essere umano interviene esattamente dove apporta più valore.
Il problema dell'automazione cieca
Un LLM può classificare un'email di supporto con il 95% di accuratezza. Sembra un numero eccellente. Finché non fai i conti: se ricevi 1.000 email al giorno, 50 sono classificate male. Se la classificazione innesca azioni automatiche — inviare un rimborso, escalare al legale, chiudere un ticket — quei 50 errori giornalieri non sono una percentuale statistica. Sono 50 clienti con un'esperienza compromessa.
Il problema peggiora con la confidenza. Un modello che sbaglia e lo sa è gestibile. Un modello che sbaglia con alta confidenza è pericoloso. I LLM sono particolarmente inclini a questo: generano risposte coerenti e ben scritte che sembrano corrette anche quando non lo sono. Le famose allucinazioni non vengono con un'etichetta di avvertimento.
L'automazione cieca amplifica gli errori alla velocità della macchina. Un essere umano che commette un errore elabora forse 100 casi al giorno. Una pipeline automatica difettosa ne elabora 10.000 prima che qualcuno se ne accorga.
I tre pattern di Human in the Loop
Non esiste un unico modello di HITL. Ci sono tre pattern fondamentali, e scegliere quello giusto dipende dal tuo caso d'uso, dalla tua tolleranza al rischio e dal costo di un errore.
Pattern 1: Human-as-Validator (revisione prima dell'azione)
L'IA elabora, classifica, genera o estrae. L'essere umano rivede e approva prima che l'azione venga eseguita. È il pattern più conservativo e quello che dovresti usare come default quando il costo di un errore è alto.
Quando usarlo:
- Elaborazione di documenti finanziari o legali
- Generazione di risposte ai clienti in contesti sensibili
- Decisioni che coinvolgono denaro (rimborsi, approvazioni di credito)
- Qualsiasi output che viene inviato al di fuori della tua organizzazione
Architettura tipica:
Input → Modello IA → Coda di revisione → Umano approva/rifiuta → Azione
↓
Feedback al modello
La chiave sta nella coda di revisione. Non è un semplice "sì/no". Un buon sistema di validazione mostra all'essere umano: l'input originale, l'output del modello, lo score di confidenza e i frammenti di contesto che il modello ha usato per prendere la decisione. L'essere umano non rivede da zero — valida il lavoro dell'IA. Questo è 10 volte più veloce che fare il lavoro manualmente.
Pattern 2: Human-as-Exception-Handler (intervento per eccezione)
L'IA elabora la maggior parte dei casi automaticamente. Scala all'essere umano solo quando rileva di non poter risolvere il caso con sufficiente confidenza, o quando il caso esce dai parametri definiti.
Quando usarlo:
- Alto volume, basso rischio per singolo caso
- Supporto tier 1 (chatbot con escalation)
- Classificazione di contenuti
- Elaborazione di documenti standardizzati
Architettura tipica:
Input → Modello IA → Confidenza > soglia?
↓ Sì ↓ No
Azione auto → Umano risolve
↓
Feedback al modello
La soglia di confidenza è la tua leva principale. Troppo alta: troppi casi vengono escalati e perdi il beneficio dell'automazione. Troppo bassa: passano errori che distruggono la fiducia dell'utente. La calibrazione è empirica — inizi in modo conservativo (soglia alta) e la abbassi gradualmente monitorando il tasso di errore nei casi automatici.
Un buon sistema di exception handling necessita di routing intelligente. Non è la stessa cosa un caso che il modello non comprende (serve un esperto di dominio) e uno in cui il modello comprende ma il rischio è alto (serve un supervisore). Progetta le tue code di escalation con questa distinzione.
Pattern 3: Human-as-Teacher (feedback loop continuo)
L'essere umano non è nel flusso operativo diretto. Invece, rivede periodicamente un campione degli output automatici, etichetta gli errori, e queste informazioni vengono usate per migliorare il modello o aggiustare i prompt.
Quando usarlo:
- Sistemi già maturi con basso tasso di errore
- Casi in cui la latenza di revisione non è accettabile
- Domini in cui il contesto cambia gradualmente (drift)
Architettura tipica:
Input → Modello IA → Azione auto (100%)
↓
Campione casuale (5-10%)
↓
Revisione periodica → Aggiustamento prompt / fine-tuning
Questo pattern richiede maturità. Non implementarlo dal primo giorno. Inizia con Human-as-Validator o Exception-Handler, e migra a Teacher quando hai dati sufficienti per dimostrare che il tasso di errore è costantemente basso.
Progettare l'handoff: dove la maggior parte fallisce
Il punto di trasferimento tra IA ed essere umano è dove la maggior parte delle implementazioni si rompe. Non per l'IA né per l'essere umano, ma per l'interfaccia tra i due.
Errori comuni:
-
Context loss: L'essere umano riceve un caso escalato senza contesto. Deve ricominciare da zero, investigare cosa è successo, perché l'IA l'ha escalato. Soluzione: passa TUTTO il contesto — input originale, ragionamento del modello, tentativi precedenti, storico dell'utente.
-
Alert fatigue: Se il 40% dei casi viene escalato, gli esseri umani iniziano ad approvare in modalità automatica senza rivedere. È peggio che non avere HITL, perché crei una falsa sensazione di sicurezza. Soluzione: mantieni il tasso di escalation sotto il 15-20%. Se è più alto, il tuo modello ha bisogno di miglioramenti, non di più esseri umani.
-
Feedback loop rotto: L'essere umano corregge gli errori ma quella correzione non torna al sistema. Lo stesso errore si ripete all'infinito. Soluzione: ogni correzione umana è un dato di addestramento. Cattura la decisione, il ragionamento, e retroalimentalo nella pipeline di miglioramento.
-
Latenza inaccettabile: Il caso aspetta in coda di revisione 4 ore. A quel punto il cliente se n'è già andato. Soluzione: definisci SLA per tipo di caso e priorità. I casi urgenti vanno in una coda fast-track con alert.
Metriche che contano in un sistema HITL
Non misurare solo l'accuratezza del modello. Misura il sistema completo:
-
Throughput effettivo: Casi risolti all'ora includendo il tempo umano. Se la tua IA elabora 1.000 casi/ora ma ne scala 300 che richiedono 15 minuti ciascuno, il tuo throughput reale è molto diverso da quello teorico.
-
Tasso di escalation: Percentuale di casi che richiedono intervento umano. Dovrebbe diminuire nel tempo se il tuo feedback loop funziona.
-
Tempo di risoluzione umana: Quanto impiega l'essere umano a risolvere un caso escalato. Se è quasi uguale al tempo senza IA, il tuo sistema di contesto sta fallendo.
-
Tasso di override: Con quale frequenza l'essere umano cambia la decisione dell'IA. Se è molto alto (>30%), il tuo modello ha bisogno di lavoro. Se è molto basso (<2%), probabilmente stai escalando troppi casi che non ne hanno bisogno.
-
Error rate post-validazione: Errori che sono passati dalla revisione umana. Sì, anche gli esseri umani commettono errori. Un buon sistema HITL riconosce questo e ha controlli a valle.
Quando NON serve HITL
Non tutto ha bisogno di un essere umano nel loop. Ci sono contesti in cui l'automazione totale è corretta:
-
Task interni a basso rischio: Riassumere riunioni, classificare documenti interni, generare bozze. Se l'errore non ha conseguenze esterne, automatizza senza paura.
-
Sistemi con rollback facile: Se puoi annullare l'azione automaticamente quando rilevi un errore, la conseguenza dell'errore è bassa.
-
Elaborazione idempotente: Se elaborare qualcosa due volte (una automatica errata + una correzione) non ha un costo significativo.
La regola generale: se l'errore arriva al cliente, al regolatore, o a un conto bancario, metti un essere umano. Se l'errore resta interno ed è correggibile, automatizza.
Implementazione pratica: stack tecnico
Un sistema HITL non richiede un'infrastruttura esotica. I componenti base:
-
Coda di messaggi (SQS, RabbitMQ, Redis Streams): Per il buffer tra IA ed essere umano. I casi aspettano qui con il loro contesto.
-
Dashboard di revisione: Un'interfaccia dove l'essere umano vede il caso, l'output dell'IA, e può approvare, rifiutare o modificare. Può essere semplice come un'app React con un backend che legge dalla coda.
-
Sistema di logging: Ogni decisione — automatica o umana — viene registrata. Input, output, confidenza del modello, decisione umana, timestamp. Questo è il tuo dataset di miglioramento.
-
Pipeline di feedback: Un processo periodico (giornaliero, settimanale) che prende le correzioni umane e le converte in miglioramenti — aggiustamenti dei prompt, esempi di few-shot, o dati di fine-tuning.
-
Alert e monitoraggio: Se il tasso di escalation sale del 20% in un'ora, qualcosa è cambiato. Se il tempo medio di risoluzione umana raddoppia, la coda è satura. Devi saperlo in tempo reale.
L'essere umano giusto nel loop
Non qualsiasi essere umano va bene. La persona che rivede gli output dell'IA ha bisogno di:
- Conoscenza del dominio: Comprendere il contesto del caso per valutare se l'output è corretto.
- Calibrazione: Sapere quando l'IA tende a sbagliare e dove prestare più attenzione.
- Disciplina: Non cadere nella tentazione di approvare tutto quando la coda cresce.
Il profilo ideale è qualcuno che faceva questo lavoro manualmente prima dell'IA. Conosce i casi limite, sa cosa può andare storto, e può rilevare errori che qualcuno senza esperienza non noterebbe.
Dalla demo alla produzione
La differenza tra una demo di IA e un sistema in produzione è precisamente questo: la gestione degli errori, l'escalation, il feedback loop, il monitoraggio. L'IA è il 30% del sistema. L'altro 70% è l'ingegneria intorno — e l'human in the loop è il pezzo centrale di quell'ingegneria.
Non è una limitazione temporanea che scomparirà quando i modelli saranno migliori. È un pattern di design fondamentale per sistemi che operano nel mondo reale, dove gli errori hanno conseguenze e la fiducia si costruisce con ogni interazione corretta.
Costruisci affinché l'IA faccia l'80% del lavoro. Progetta affinché l'essere umano apporti il 20% di giudizio che trasforma un sistema impressionante in uno affidabile.
Stai progettando un sistema di IA che deve funzionare in produzione, non solo in una demo? Parla con un CTO — i nostri ingegneri hanno implementato pipeline HITL in produzione per aziende reali.