Human in the Loop : Pourquoi les Meilleures Implémentations d'IA N'Éliminent Pas l'Humain
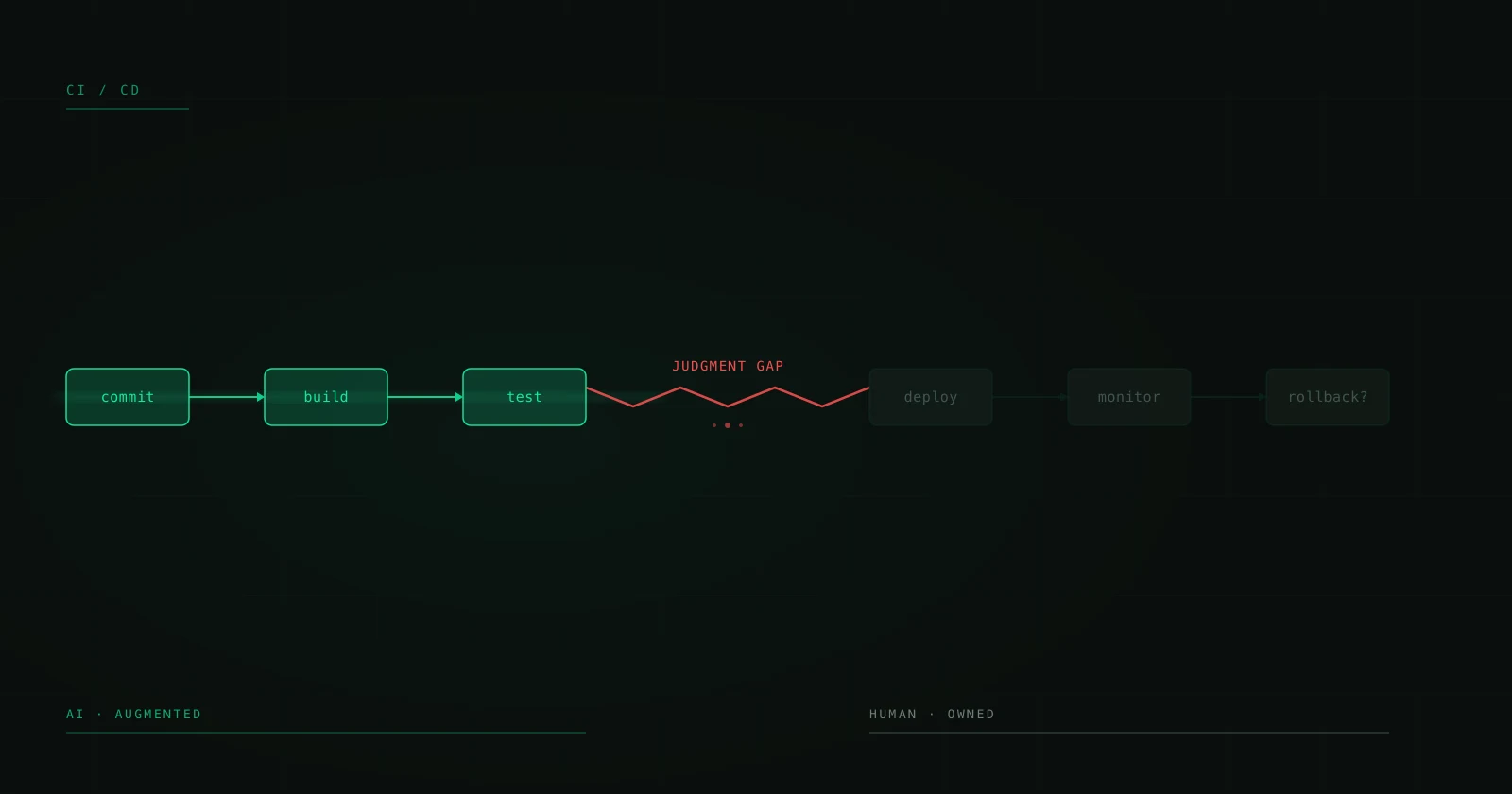
Il y a un discours dangereux dans l'écosystème de l'IA : l'objectif serait d'éliminer l'humain du processus. Automatisation totale. End-to-end AI. Zero-touch workflows. Ça sonne spectaculaire dans un pitch deck. En production, c'est la recette pour des désastres silencieux qui scalent plus vite que n'importe quel bug que vous ayez jamais vu.
Les systèmes d'IA qui fonctionnent réellement en production — ceux qui traitent des milliers de transactions par jour sans provoquer de crise — ont quelque chose en commun : ils gardent un humain dans la boucle. Pas par limitation technique, mais par design. Parce qu'il y a des décisions qu'un modèle ne devrait pas prendre seul, des contextes qu'il ne peut pas évaluer, et des erreurs qu'il ne peut pas détecter en lui-même.
Ceci n'est pas un article sur le fait que l'IA n'est pas prête. Elle l'est plus que jamais. C'est un article sur comment concevoir des systèmes où l'IA fait le gros du travail et l'humain intervient exactement là où il apporte le plus de valeur.
Le problème de l'automatisation aveugle
Un LLM peut classifier un email de support avec 95% de précision. Ça semble être un excellent chiffre. Jusqu'à ce que vous fassiez le calcul : si vous recevez 1 000 emails par jour, 50 sont mal classifiés. Si la classification déclenche des actions automatiques — envoyer un remboursement, escalader au juridique, fermer un ticket — ces 50 erreurs quotidiennes ne sont pas un pourcentage statistique. Ce sont 50 clients avec une expérience cassée.
Le problème s'aggrave avec la confiance. Un modèle qui se trompe et le sait est gérable. Un modèle qui se trompe avec une confiance élevée est dangereux. Les LLMs sont particulièrement sujets à cela : ils génèrent des réponses cohérentes et bien rédigées qui semblent correctes même quand elles ne le sont pas. Les fameuses hallucinations ne viennent pas avec une étiquette d'avertissement.
L'automatisation aveugle amplifie les erreurs à la vitesse de la machine. Un humain qui commet une erreur traite peut-être 100 cas par jour. Un pipeline automatique défectueux en traite 10 000 avant que quelqu'un ne s'en aperçoive.
Les trois patterns du Human in the Loop
Il n'existe pas un seul modèle de HITL. Il y a trois patterns fondamentaux, et choisir le bon dépend de votre cas d'usage, de votre tolérance au risque et du coût d'une erreur.
Pattern 1 : Human-as-Validator (révision avant action)
L'IA traite, classifie, génère ou extrait. L'humain révise et approuve avant que l'action ne s'exécute. C'est le pattern le plus conservateur et celui que vous devriez utiliser par défaut quand le coût d'une erreur est élevé.
Quand l'utiliser :
- Traitement de documents financiers ou juridiques
- Génération de réponses aux clients dans des contextes sensibles
- Décisions qui impliquent de l'argent (remboursements, approbations de crédit)
- Tout output envoyé en dehors de votre organisation
Architecture typique :
Input → Modèle IA → File de révision → Humain approuve/rejette → Action
↓
Feedback au modèle
La clé réside dans la file de révision. Ce n'est pas un simple "oui/non". Un bon système de validation montre à l'humain : l'input original, l'output du modèle, le score de confiance, et les fragments de contexte que le modèle a utilisés pour prendre la décision. L'humain ne révise pas à partir de zéro — il valide le travail de l'IA. C'est 10x plus rapide que de faire le travail manuellement.
Pattern 2 : Human-as-Exception-Handler (intervention par exception)
L'IA traite la majorité des cas automatiquement. Elle n'escalade à l'humain que lorsqu'elle détecte qu'elle ne peut pas résoudre le cas avec suffisamment de confiance, ou quand le cas sort des paramètres définis.
Quand l'utiliser :
- Volume élevé, faible risque par cas individuel
- Support tier 1 (chatbots avec escalade)
- Classification de contenu
- Traitement de documents standardisés
Architecture typique :
Input → Modèle IA → Confiance > seuil ?
↓ Oui ↓ Non
Action auto → Humain résout
↓
Feedback au modèle
Le seuil de confiance est votre levier principal. Trop élevé : trop de cas escaladent et vous perdez le bénéfice de l'automatisation. Trop bas : des erreurs passent et détruisent la confiance de l'utilisateur. La calibration est empirique — vous commencez conservateur (seuil élevé) et vous descendez graduellement en monitorant le taux d'erreurs sur les cas automatiques.
Un bon système d'exception handling nécessite un routing intelligent. Un cas que le modèle ne comprend pas (nécessite un expert du domaine) n'est pas la même chose qu'un cas que le modèle comprend mais dont le risque est élevé (nécessite un superviseur). Concevez vos files d'escalade avec cette distinction.
Pattern 3 : Human-as-Teacher (feedback loop continu)
L'humain n'est pas dans le flux opérationnel direct. À la place, il révise périodiquement un échantillon des outputs automatiques, étiquette les erreurs, et ces informations sont utilisées pour améliorer le modèle ou ajuster les prompts.
Quand l'utiliser :
- Systèmes déjà matures avec un faible taux d'erreur
- Cas où la latence de révision n'est pas acceptable
- Domaines où le contexte change graduellement (drift)
Architecture typique :
Input → Modèle IA → Action auto (100%)
↓
Échantillon aléatoire (5-10%)
↓
Révision périodique → Ajustement de prompts / fine-tuning
Ce pattern nécessite de la maturité. Ne l'implémentez pas dès le jour 1. Commencez avec Human-as-Validator ou Exception-Handler, et migrez vers Teacher quand vous aurez suffisamment de données pour démontrer que le taux d'erreur est systématiquement bas.
Concevoir le handoff : là où la plupart échouent
Le point de transfert entre IA et humain est là où la plupart des implémentations se cassent. Pas à cause de l'IA ni de l'humain, mais à cause de l'interface entre les deux.
Erreurs courantes :
-
Context loss : L'humain reçoit un cas escaladé sans contexte. Il doit repartir de zéro, investiguer ce qui s'est passé, comprendre pourquoi l'IA l'a escaladé. Solution : passez TOUT le contexte — input original, raisonnement du modèle, tentatives précédentes, historique de l'utilisateur.
-
Alert fatigue : Si 40% des cas sont escaladés, les humains commencent à approuver en mode automatique sans vérifier. C'est pire que de ne pas avoir de HITL, car vous créez un faux sentiment de sécurité. Solution : maintenez le taux d'escalade en dessous de 15-20%. S'il est plus élevé, votre modèle a besoin d'améliorations, pas de plus d'humains.
-
Feedback loop cassé : L'humain corrige des erreurs mais cette correction ne revient pas au système. La même erreur se répète indéfiniment. Solution : chaque correction humaine est une donnée d'entraînement. Capturez la décision, le raisonnement, et réinjectez-les dans le pipeline d'amélioration.
-
Latence inacceptable : Le cas attend dans la file de révision pendant 4 heures. À ce moment-là, le client est déjà parti. Solution : définissez des SLAs par type de cas et priorité. Les cas urgents vont dans une file fast-track avec des alertes.
Métriques qui comptent dans un système HITL
Ne mesurez pas seulement la précision du modèle. Mesurez le système complet :
-
Throughput effectif : Cas résolus par heure incluant le temps humain. Si votre IA traite 1 000 cas/heure mais en escalade 300 qui prennent 15 minutes chacun, votre throughput réel est très différent du théorique.
-
Taux d'escalade : Pourcentage de cas nécessitant une intervention humaine. Il devrait baisser avec le temps si votre feedback loop fonctionne.
-
Temps de résolution humaine : Combien de temps l'humain met à résoudre un cas escaladé. S'il est presque égal au temps sans IA, votre système de contexte ne fonctionne pas.
-
Taux d'override : À quelle fréquence l'humain change la décision de l'IA. S'il est très élevé (>30%), votre modèle a besoin de travail. S'il est très bas (<2%), vous escaladez probablement trop de cas qui n'en ont pas besoin.
-
Taux d'erreur post-validation : Erreurs ayant passé la révision humaine. Oui, les humains aussi font des erreurs. Un bon système HITL le reconnaît et dispose de checks en aval.
Quand vous N'avez PAS besoin de HITL
Tout ne nécessite pas un humain dans la boucle. Il y a des contextes où l'automatisation totale est appropriée :
-
Tâches internes à faible risque : Résumer des réunions, classifier des documents internes, générer des brouillons. Si l'erreur n'a pas de conséquences externes, automatisez sans crainte.
-
Systèmes avec rollback facile : Si vous pouvez annuler l'action automatiquement quand vous détectez une erreur, la conséquence de l'erreur est faible.
-
Traitement idempotent : Si traiter quelque chose deux fois (une automatique incorrecte + une correction) n'a pas de coût significatif.
La règle générale : si l'erreur atteint le client, le régulateur, ou un compte bancaire, mettez un humain. Si l'erreur reste interne et est corrigible, automatisez.
Implémentation pratique : stack technique
Un système HITL ne nécessite pas d'infrastructure exotique. Les composants de base :
-
File de messages (SQS, RabbitMQ, Redis Streams) : Pour le buffer entre IA et humain. Les cas y attendent avec leur contexte.
-
Dashboard de révision : Une interface où l'humain voit le cas, l'output de l'IA, et peut approuver, rejeter ou éditer. Ça peut être aussi simple qu'une app React avec un backend qui lit depuis la file.
-
Système de logging : Chaque décision — automatique ou humaine — est enregistrée. Input, output, confiance du modèle, décision humaine, timestamp. C'est votre dataset d'amélioration.
-
Pipeline de feedback : Un processus périodique (quotidien, hebdomadaire) qui prend les corrections humaines et les transforme en améliorations — ajustements de prompts, exemples de few-shot, ou données de fine-tuning.
-
Alertes et monitoring : Si le taux d'escalade augmente de 20% en une heure, quelque chose a changé. Si le temps moyen de résolution humaine double, la file est saturée. Vous devez le savoir en temps réel.
Le bon humain dans la boucle
N'importe quel humain ne convient pas. La personne qui révise les outputs de l'IA doit avoir :
- Connaissance du domaine : Comprendre le contexte du cas pour évaluer si l'output est correct.
- Calibration : Savoir quand l'IA a tendance à se tromper et où porter plus d'attention.
- Discipline : Ne pas céder à la tentation d'approuver tout quand la file grossit.
Le profil idéal est quelqu'un qui faisait ce travail manuellement avant l'IA. Il connaît les edge cases, sait ce qui peut mal tourner, et peut détecter des erreurs que quelqu'un sans expérience laisserait passer.
De la démo à la production
La différence entre une démo d'IA et un système en production est précisément cela : la gestion des erreurs, l'escalade, le feedback loop, le monitoring. L'IA représente 30% du système. Les 70% restants sont l'ingénierie autour — et le human in the loop est la pièce centrale de cette ingénierie.
Ce n'est pas une limitation temporaire qui disparaîtra quand les modèles seront meilleurs. C'est un pattern de conception fondamental pour les systèmes qui opèrent dans le monde réel, où les erreurs ont des conséquences et la confiance se construit à chaque interaction correcte.
Construisez pour que l'IA fasse 80% du travail. Concevez pour que l'humain apporte les 20% de jugement qui transforment un système impressionnant en un système fiable.
Vous concevez un système d'IA qui doit fonctionner en production, pas seulement en démo ? Parlez à un CTO — nos ingénieurs ont déployé des pipelines HITL en production pour de vraies entreprises.