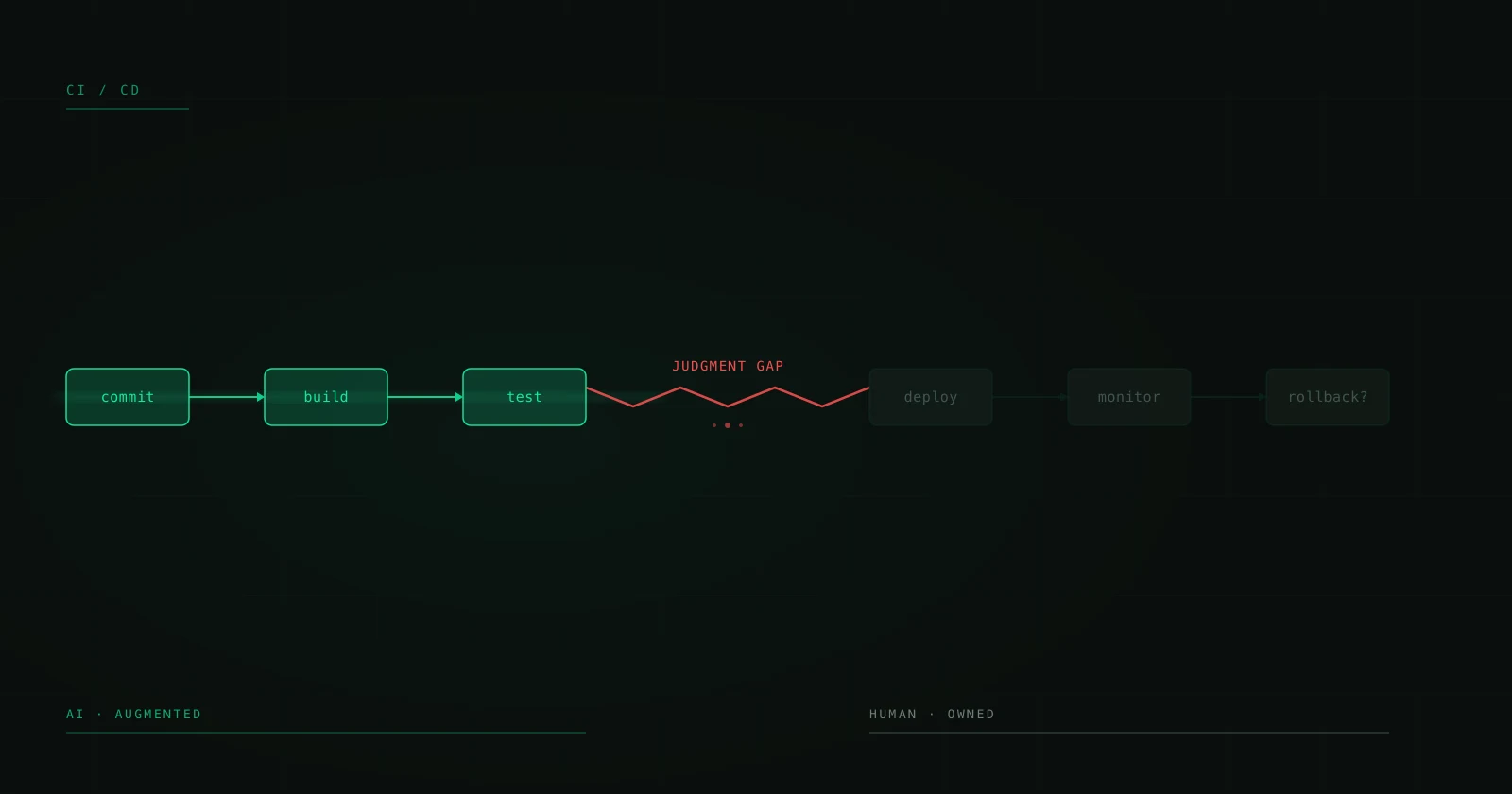
Human in the loop: por qué las mejores implementaciones de IA no prescinden del humano
Hay una narrativa peligrosa en el ecosistema de IA: que el objetivo es eliminar al humano del proceso. Automatización total. End-to-end AI. Zero-touch workflows. Suena espectacular en un pitch deck. En producción, es la receta para desastres silenciosos que escalan más rápido que cualquier bug que hayas visto.
Los sistemas de IA que he visto aguantar en producción — los que procesan miles de transacciones al día sin provocar crisis — tienen algo en común: mantienen a un humano en el loop. No por limitación técnica, sino por diseño. Porque hay decisiones que un modelo no debería tomar solo, contextos que no puede evaluar, y errores que no puede detectar en sí mismo.
Esto no es un artículo sobre por qué la IA no está lista. Está más que lista. Esto es sobre cómo diseñar sistemas donde la IA hace el trabajo pesado y el humano interviene exactamente donde aporta más valor.
El problema de la automatización ciega
Un LLM puede clasificar un email de soporte con 95% de precisión. Parece un número excelente. Hasta que haces las cuentas: si recibes 1.000 emails al día, 50 están mal clasificados. Si esa clasificación dispara acciones automáticas — emitir un reembolso, escalar a legal, cerrar un ticket — esos 50 errores diarios no son un porcentaje estadístico. Son 50 clientes con una experiencia rota.
El problema se agrava con la confianza. Un modelo que se equivoca y lo sabe es gestionable. Un modelo que se equivoca con alta confianza es peligroso. Los LLMs son particularmente propensos a esto: generan respuestas coherentes y bien redactadas que parecen correctas incluso cuando no lo son. Las famosas alucinaciones no vienen con una etiqueta de advertencia.
La automatización ciega amplifica errores a velocidad de máquina. Un humano que se equivoca procesa quizá 100 casos al día. Un pipeline automático defectuoso procesa 10.000 antes de que nadie se dé cuenta.
Los tres patrones de Human in the Loop
No existe un único modelo de HITL. Hay tres patrones fundamentales, y elegir el correcto depende de tu caso de uso, tu tolerancia al riesgo y el coste de un error.
Patrón 1: Human-as-Validator (revisión antes de acción)
La IA procesa, clasifica, genera o extrae. El humano revisa y aprueba antes de que la acción se ejecute. Es el patrón más conservador y el que deberías usar por defecto cuando el coste de un error es alto.
Cuándo usarlo:
- Procesamiento de documentos financieros o legales
- Generación de respuestas a clientes en contextos sensibles
- Decisiones que implican dinero (reembolsos, aprobaciones de crédito)
- Cualquier output que se envía fuera de tu organización
Arquitectura típica:
Input → Modelo IA → Cola de revisión → Humano aprueba/rechaza → Acción
↓
Feedback al modelo
La clave está en la cola de revisión. No es un simple "sí/no". Un buen sistema de validación muestra al humano: el input original, el output del modelo, el score de confianza, y los fragmentos de contexto que el modelo usó para decidir. El humano no revisa desde cero — valida el trabajo de la IA. Eso es varias veces más rápido que hacer el trabajo a mano.
Patrón 2: Human-as-Exception-Handler (intervención por excepción)
La IA procesa la mayoría de casos automáticamente. Solo escala al humano cuando detecta que no puede resolver el caso con suficiente confianza, o cuando el caso cae fuera de los parámetros definidos.
Cuándo usarlo:
- Alto volumen, bajo riesgo por caso individual
- Soporte tier 1 (chatbots con escalado a humano)
- Clasificación de contenido
- Procesamiento de documentos estandarizados
Arquitectura típica:
Input → Modelo IA → ¿Confianza > umbral?
↓ Sí ↓ No
Acción auto → Humano resuelve
↓
Feedback al modelo
El umbral de confianza es tu palanca principal. Demasiado alto: demasiados casos escalan y pierdes el beneficio de la automatización. Demasiado bajo: se cuelan errores que destruyen la confianza del usuario. La calibración es empírica — empieza siendo conservador (umbral alto) y bájalo gradualmente mientras monitorizas la tasa de error de los casos automáticos.
Un buen sistema de exception handling necesita routing inteligente. No es lo mismo un caso que el modelo no entiende (necesita un experto de dominio) que uno donde el modelo entiende pero el riesgo es alto (necesita un supervisor). Diseña tus colas de escalado con esta distinción en mente.
Patrón 3: Human-as-Teacher (feedback loop continuo)
El humano no está en el flujo operativo directo. En cambio, revisa periódicamente una muestra de los outputs automáticos, etiqueta errores, y esa información se usa para mejorar el modelo o ajustar los prompts.
Cuándo usarlo:
- Sistemas ya maduros con baja tasa de error
- Casos donde la latencia de revisión no es aceptable
- Dominios donde el contexto cambia gradualmente (drift)
Arquitectura típica:
Input → Modelo IA → Acción auto (100%)
↓
Muestra aleatoria (5-10%)
↓
Revisión periódica → Ajuste de prompts / fine-tuning
Este patrón requiere madurez. No lo implementes desde el día 1. Empieza con Human-as-Validator o Exception-Handler, y migra a Teacher cuando tengas datos suficientes para demostrar que la tasa de error es consistentemente baja.
El diseño del handoff: donde fallan casi todos
El punto de transferencia entre IA y humano es donde se rompen la mayoría de las implementaciones que he revisado. No por la IA ni por el humano, sino por la interfaz entre ambos.
Errores comunes:
-
Pérdida de contexto: El humano recibe un caso escalado sin contexto. Tiene que empezar de cero, investigar qué pasó, por qué la IA lo escaló. Solución: pasa TODO el contexto — input original, razonamiento del modelo, intentos previos, historial del usuario.
-
Fatiga de alertas: Si el 40% de los casos se escalan, los humanos empiezan a aprobar en piloto automático, sin revisar. Es peor que no tener HITL, porque crea una falsa sensación de seguridad. Solución: mantén la tasa de escalado por debajo del 15-20%. Si es más alta, tu modelo necesita mejoras, no más humanos.
-
Feedback loop roto: El humano corrige errores pero esa corrección no vuelve al sistema. El mismo error se repite indefinidamente. Solución: cada corrección humana es un dato de entrenamiento. Captura la decisión, el razonamiento, y retroaliméntalo al pipeline de mejora.
-
Latencia inaceptable: El caso se pasa 4 horas en la cola de revisión. Para entonces, el cliente ya se ha ido. Solución: define SLAs por tipo de caso y prioridad. Los casos urgentes van a una cola fast-track con alertas.
Métricas que importan en un sistema HITL
No midas solo la precisión del modelo. Mide el sistema completo:
-
Throughput efectivo: Casos resueltos por hora incluyendo el tiempo humano. Si tu IA procesa 1.000 casos/hora pero escala 300 que tardan 15 minutos cada uno, tu throughput real es muy diferente del teórico.
-
Tasa de escalado: Porcentaje de casos que requieren intervención humana. Debería bajar con el tiempo si tu feedback loop funciona.
-
Tiempo de resolución humana: Cuánto tarda el humano en resolver un caso escalado. Si es casi igual al tiempo sin IA, tu sistema de contexto está fallando.
-
Tasa de override: Con qué frecuencia el humano cambia la decisión de la IA. Si es muy alta (>30%), tu modelo necesita trabajo. Si es muy baja (<2%), probablemente estás escalando demasiados casos que no lo necesitan.
-
Tasa de error post-validación: Errores que pasaron la revisión humana. Sí, los humanos también se equivocan. Un buen sistema HITL lo asume y tiene comprobaciones aguas abajo.
Cuándo NO necesitas HITL
No todo necesita un humano en el loop. Hay contextos donde la automatización total es correcta:
-
Tareas internas de bajo riesgo: Resumir reuniones, clasificar documentos internos, generar borradores. Si el error no tiene consecuencias externas, automatiza sin miedo.
-
Sistemas con rollback fácil: Si puedes deshacer la acción automáticamente cuando detectas un error, la consecuencia del error es baja.
-
Procesamiento idempotente: Si procesar algo dos veces (una automática incorrecta + una corrección) no tiene coste significativo.
La regla general: si el error llega al cliente, al regulador o a una cuenta bancaria, pon a un humano en medio. Si el error se queda dentro y es corregible, automatiza.
El stack: nada exótico
Un sistema HITL no requiere infraestructura exótica. Los componentes básicos:
-
Cola de mensajes (SQS, RabbitMQ, Redis Streams): Para el buffer entre IA y humano. Los casos esperan aquí con su contexto.
-
Dashboard de revisión: Una interfaz donde el humano ve el caso, el output de la IA, y puede aprobar, rechazar o editar. Puede ser tan simple como una app React con un backend que lee de la cola.
-
Sistema de logging: Cada decisión — automática o humana — queda registrada. Input, output, confianza del modelo, decisión humana, timestamp. Esto es tu dataset de mejora.
-
Pipeline de feedback: Un proceso periódico (diario, semanal) que toma las correcciones humanas y las convierte en mejoras — ajustes de prompts, ejemplos de few-shot, o datos de fine-tuning.
-
Alertas y monitorización: Si la tasa de escalado se dispara un 20% en una hora, algo ha cambiado. Si el tiempo medio de resolución humana se duplica, la cola está saturada. Necesitas saberlo en tiempo real.
El humano adecuado en el loop
No sirve cualquier humano. La persona que revisa los outputs de la IA necesita:
- Conocimiento de dominio: Entender el contexto del caso para evaluar si el output es correcto.
- Calibración: Saber cuándo la IA suele fallar y dónde poner más atención.
- Disciplina: No caer en la tentación de aprobar todo cuando la cola crece.
El perfil ideal es alguien que hacía este trabajo manualmente antes de la IA. Conoce los edge cases, sabe qué puede salir mal, y puede detectar errores que alguien sin experiencia pasaría por alto.
De demo a producción
La diferencia entre una demo de IA y un sistema en producción es precisamente esto: la gestión de errores, el escalado, los feedback loops, la monitorización. La IA es el 30% del sistema. El otro 70% es la ingeniería de alrededor — y el human in the loop es la pieza central de esa ingeniería.
No es una limitación temporal que desaparecerá cuando los modelos mejoren. Es un patrón de diseño fundamental para sistemas que operan en el mundo real, donde los errores tienen consecuencias y la confianza se construye con cada interacción correcta.
Construye para que la IA haga el 80% del trabajo. Diseña para que el humano aporte el 20% de juicio que convierte un sistema impresionante en uno fiable.
¿Estás diseñando un sistema de IA que necesita funcionar en producción, no solo en una demo? Habla con un CTO — nuestros ingenieros han desplegado pipelines HITL en producción para empresas reales.