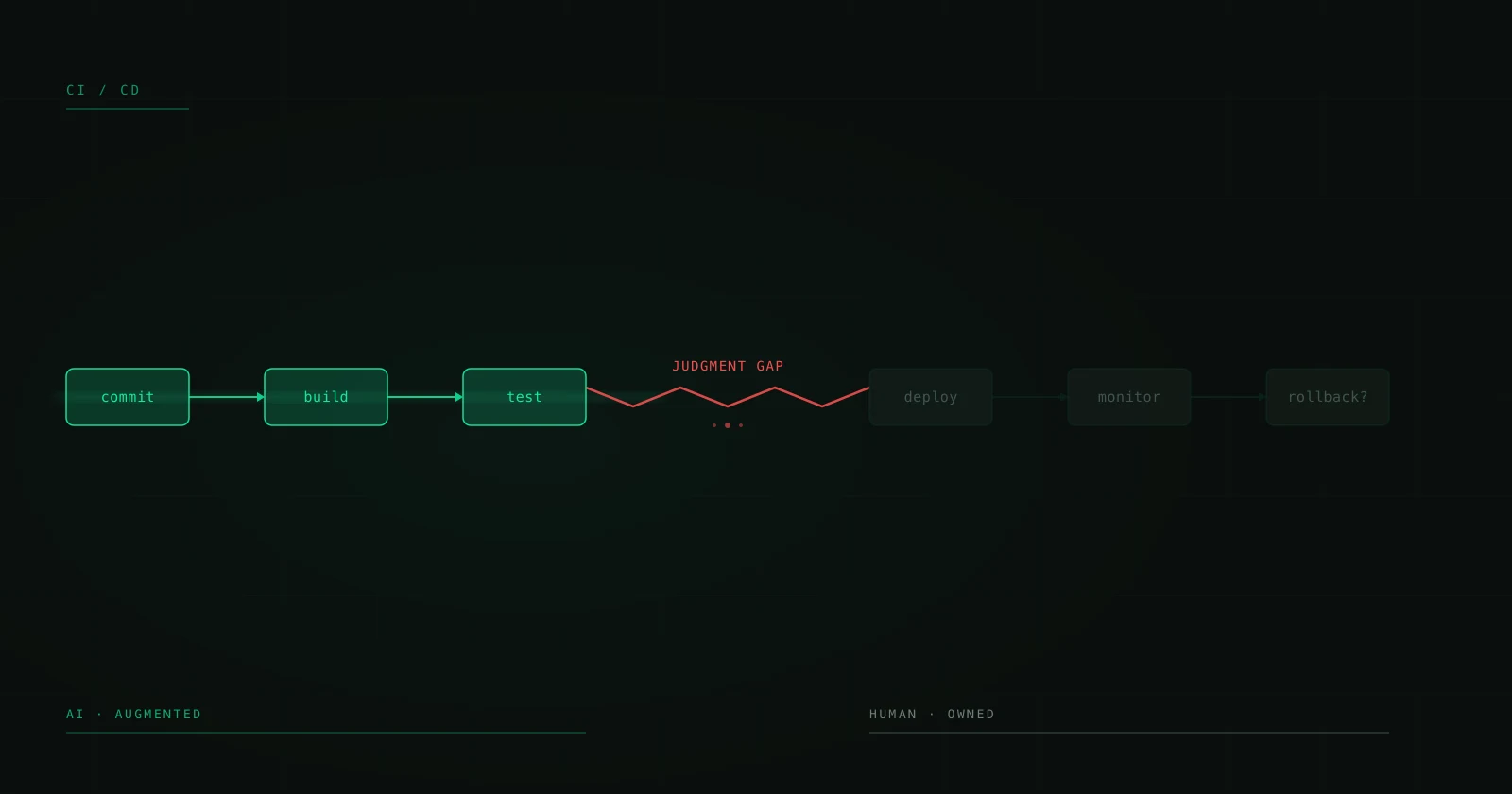
Human in the Loop: per què les millors implementacions d'IA no eliminen l'humà
Hi ha una narrativa perillosa a l'ecosistema d'IA: que l'objectiu és eliminar l'humà del procés. Automatització total. End-to-end AI. Zero-touch workflows. Sona espectacular en un pitch deck. En producció, és la recepta per a desastres silenciosos que escalen més de pressa que cap bug que hagis vist mai.
Els sistemes d'IA que he vist aguantar en producció — els que processen milers de transaccions al dia sense provocar cap crisi — tenen una cosa en comú: mantenen un humà al loop. No per limitacions tècniques, sinó per disseny. Perquè hi ha decisions que un model no hauria de prendre tot sol, contextos que no pot avaluar i errors que no es pot detectar a si mateix.
Això no és un article sobre per què la IA no està a punt. Ho està de sobres. Va de com dissenyar sistemes on la IA fa la feina pesada i l'humà intervé exactament allà on aporta més valor.
El problema de l'automatització cega
Un LLM pot classificar un email de suport amb un 95% de precisió. Sembla una xifra excel·lent. Fins que fas números: si reps 1.000 emails al dia, n'hi ha 50 de mal classificats. Si la classificació desencadena accions automàtiques — emetre un reemborsament, escalar a legal, tancar un ticket — aquests 50 errors diaris no són un percentatge estadístic. Són 50 clients amb una experiència trencada.
El problema s'agreuja amb la confiança. Un model que s'equivoca i ho sap és gestionable. Un model que s'equivoca amb alta confiança és perillós. Els LLMs són particularment propensos a això: generen respostes coherents i ben redactades que semblen correctes fins i tot quan no ho són. Les famoses al·lucinacions no porten etiqueta d'advertència.
L'automatització cega amplifica els errors a velocitat de màquina. Un humà que s'equivoca processa potser 100 casos al dia. Un pipeline automàtic defectuós processa 10.000 abans que algú se n'adoni.
Els tres patrons de Human in the Loop
No existeix un únic model de HITL. Hi ha tres patrons fonamentals, i triar el correcte depèn del cas d'ús, de la tolerància al risc i del cost d'un error.
Patró 1: Human-as-Validator (revisió abans de l'acció)
La IA processa, classifica, genera o extreu. L'humà revisa i aprova abans que l'acció s'executi. És el patró més conservador i el que hauries de fer servir per defecte quan el cost d'un error és alt.
Quan fer-lo servir:
- Processament de documents financers o legals
- Generació de respostes a clients en contextos sensibles
- Decisions que impliquen diners (reemborsaments, aprovacions de crèdit)
- Qualsevol output que s'enviï fora de l'organització
Arquitectura típica:
Input → Model IA → Cua de revisió → Humà aprova/rebutja → Acció
↓
Feedback al model
La clau és la cua de revisió. No és un simple «sí/no». Un bon sistema de validació mostra a l'humà l'input original, l'output del model, la puntuació de confiança i els fragments de context que el model ha fet servir per decidir. L'humà no revisa des de zero — valida la feina de la IA. I això és unes quantes vegades més ràpid que fer la feina a mà.
Patró 2: Human-as-Exception-Handler (intervenció per excepció)
La IA processa la majoria de casos automàticament. Només escala a l'humà quan detecta que no pot resoldre el cas amb prou confiança, o quan el cas cau fora dels paràmetres definits.
Quan fer-lo servir:
- Alt volum, baix risc per cas individual
- Suport tier 1 (chatbots amb escalació)
- Classificació de contingut
- Processament de documents estandarditzats
Arquitectura típica:
Input → Model IA → Confiança > llindar?
↓ Sí ↓ No
Acció auto → Humà resol
↓
Feedback al model
El llindar de confiança és la palanca principal. Massa alt: s'escalen massa casos i perds el benefici de l'automatització. Massa baix: se't colen errors que destrueixen la confiança de l'usuari. El calibratge és empíric — comença conservador (llindar alt) i abaixa'l gradualment mentre monitoritzes la taxa d'error dels casos automàtics.
Un bon sistema d'exception handling necessita routing intel·ligent. No és el mateix un cas que el model no entén (necessita un expert de domini) que un on el model entén però el risc és alt (necessita un supervisor). Dissenya les teves cues d'escalació amb aquesta distinció.
Patró 3: Human-as-Teacher (feedback loop continu)
L'humà no és al flux operatiu directe: revisa periòdicament una mostra dels outputs automàtics, n'etiqueta els errors, i aquesta informació serveix per millorar el model o ajustar els prompts.
Quan fer-lo servir:
- Sistemes ja madurs amb baixa taxa d'error
- Casos on la latència de revisió no és acceptable
- Dominis on el context canvia gradualment (drift)
Arquitectura típica:
Input → Model IA → Acció auto (100%)
↓
Mostra aleatòria (5-10%)
↓
Revisió periòdica → Ajust de prompts / fine-tuning
Aquest patró requereix maduresa. No l'implementis des del dia 1. Comença amb Human-as-Validator o Exception-Handler, i migra a Teacher quan tinguis dades suficients per demostrar que la taxa d'error és consistentment baixa.
Dissenyar el handoff: on falla la majoria
El punt de transferència entre la IA i l'humà és on es trenquen la majoria de les implementacions que he revisat. No per culpa de la IA ni de l'humà, sinó de la interfície entre tots dos.
Errors comuns:
-
Pèrdua de context: L'humà rep un cas escalat sense context. Ha de partir de zero, investigar què ha passat i per què la IA l'ha escalat. Solució: passa-li TOT el context — input original, raonament del model, intents previs, historial de l'usuari.
-
Fatiga d'alertes: Si s'escala el 40% dels casos, els humans comencen a aprovar amb el pilot automàtic posat, sense revisar res. Això és pitjor que no tenir HITL, perquè crea una falsa sensació de seguretat. Solució: mantén la taxa d'escalació per sota del 15-20%. Si és més alta, el que necessita millores és el model, no pas més humans.
-
Feedback loop trencat: L'humà corregeix errors, però la correcció no torna mai al sistema. El mateix error es repeteix indefinidament. Solució: cada correcció humana és una dada d'entrenament. Captura la decisió i el raonament, i retorna-ho al pipeline de millora.
-
Latència inacceptable: El cas es passa 4 hores a la cua de revisió. Quan algú el mira, el client ja ha marxat. Solució: defineix SLA per tipus de cas i prioritat. Els casos urgents van a una cua fast-track amb alertes.
Mètriques que importen en un sistema HITL
No mesuris només la precisió del model. Mesura el sistema complet:
-
Throughput efectiu: Casos resolts per hora incloent-hi el temps humà. Si la IA et processa 1.000 casos/hora però n'escala 300 que demanen 15 minuts cadascun, el throughput real no s'assembla gens al teòric.
-
Taxa d'escalació: Percentatge de casos que requereixen intervenció humana. Hauria de baixar amb el temps si el teu feedback loop funciona.
-
Temps de resolució humana: Quant triga l'humà a resoldre un cas escalat. Si és gairebé el mateix que sense IA, el sistema de context està fallant.
-
Taxa d'override: Amb quina freqüència l'humà canvia la decisió de la IA. Si és molt alta (>30%), el model necessita feina. Si és molt baixa (<2%), probablement estàs escalant massa casos que no ho necessiten.
-
Taxa d'error postvalidació: Errors que han passat la revisió humana. Sí, els humans també s'equivoquen. Un bon sistema HITL ho assumeix i preveu comprovacions posteriors.
Quan NO necessites HITL
No tot necessita un humà al loop. Hi ha contextos on l'automatització total és correcta:
-
Tasques internes de baix risc: Resumir reunions, classificar documents interns, generar esborranys. Si l'error no té conseqüències externes, automatitza sense por.
-
Sistemes amb rollback fàcil: Si pots desfer l'acció automàticament quan detectes un error, la conseqüència de l'error és baixa.
-
Processament idempotent: Si processar una cosa dues vegades (una d'automàtica incorrecta + una correcció) no té un cost significatiu.
La regla general: si l'error arriba al client, al regulador, o a un compte bancari, posa-hi un humà. Si l'error es queda intern i és corregible, automatitza.
L'stack: no cal res d'exòtic
Un sistema HITL no requereix infraestructura exòtica. Els components bàsics:
-
Cua de missatges (SQS, RabbitMQ, Redis Streams): Per al buffer entre IA i humà. Els casos esperen aquí amb el seu context.
-
Dashboard de revisió: Una interfície on l'humà veu el cas, l'output de la IA, i pot aprovar, rebutjar o editar. Pot ser tan simple com una app React amb un backend que llegeix de la cua.
-
Sistema de logging: Cada decisió — automàtica o humana — queda registrada. Input, output, confiança del model, decisió humana, timestamp. Això és el teu dataset de millora.
-
Pipeline de feedback: Un procés periòdic (diari, setmanal) que pren les correccions humanes i les converteix en millores — ajustos de prompts, exemples de few-shot, o dades de fine-tuning.
-
Alertes i monitoratge: Si la taxa d'escalació puja un 20% en una hora, alguna cosa ha canviat. Si el temps mitjà de resolució humana es duplica, la cua està saturada. Necessites saber-ho en temps real.
L'humà adequat al loop
No serveix qualsevol humà. La persona que revisa outputs d'IA necessita:
- Coneixement de domini: Entendre el context del cas per avaluar si l'output és correcte.
- Calibratge: Saber quan la IA sol fallar i on cal parar més atenció.
- Disciplina: No caure en la temptació d'aprovar-ho tot quan la cua creix.
El perfil ideal és algú que feia aquesta feina a mà abans de la IA. Coneix els edge cases, sap què pot fallar i detecta errors que algú sense experiència passaria per alt.
De demo a producció
La diferència entre una demo d'IA i un sistema en producció és exactament això: la gestió d'errors, l'escalació, els feedback loops, el monitoratge. La IA és el 30% del sistema. L'altre 70% és l'enginyeria que l'envolta — i el human in the loop és la peça central d'aquesta enginyeria.
No és una limitació temporal que desapareixerà quan els models millorin. És un patró de disseny fonamental per a sistemes que operen al món real, on els errors tenen conseqüències i la confiança es construeix amb cada interacció correcta.
Construeix perquè la IA faci el 80% de la feina. Dissenya perquè l'humà hi posi el 20% de judici que converteix un sistema impressionant en un sistema fiable.
Estàs dissenyant un sistema d'IA que necessita funcionar en producció, no només en una demo? Parla amb un CTO — els nostres enginyers han desplegat pipelines HITL en producció per a empreses reals.